쿠버네티스 오퍼레이터를 MySQL Cluster를 통해 알아보자
쿠버네티스 오퍼레이터란 무엇인가?
먼저 오퍼레이터 디자인 패턴에 대해 살펴볼 필요가 있다. 오퍼레이터는 CoreOS 블로그 아티클을 참고하면 알 수 있는 디자인 패턴이다. 운영자의 역할을 소프트웨어에 적용한 개념인데, 상태를 수동적으로 관리해주어야 하는 SRE 엔지니어링의 한계를 극복하기 위해 고안되었다고 할 수 있다. 다음 장표를 보자.

오퍼레이터의 패턴은 우리가 관리하고자 하는 애플리케이션이나 인프라가 있을 때, 사용자가 선언적인 방법으로 이상적인 상태를 지정할 수 있어야 하고, 계속 for-loop 형태로 도는 컨트롤러가 있어서 상태를 인지하고 읽을 수 있어야 한다.
> Technically, there is no difference between a typical controller and an operator. Often the difference referred to is the operational knowledge that is included in the operator.
As a result, a controller which spins up a pod when a custom resource is created and the pod gets destroyed afterwards can be described as a simple controller. If the controller has additional operational knowledge like how to upgrade or remediate from errors, it is an operator. — CNCF 오퍼레이터 백서

쿠버네티스에서는 컨트롤러라는 개념이 있는데, 이상적인 상태를 유지하기 위해서 반복적인 작업을 담당하는 친구이다. 배포하는 컨트롤러가 있다고 했을 때, 사용자가 사전에 설정한 파드 복제본의 수가 지속적으로 실행될 수 있도록 하는 것이 컨트롤러의 임무다. 따라서 실패하거나 삭제한 파드를 인지해서 새로운 파드가 돌도록 구성할 수 있게 된다. 에러 발생 시에는 어떠한 롤백 처리가 되어야 하고, 파드들이 어떻게 업그레이드가 되는 지 등을 명시하는 운영 노하우가 담기면 비로소 오퍼레이터 패턴의 철학을 접목했다고 말할 수 있다. 이렇게 이상적인 상태와 현재 상태를 이어주는 역할을 하는 것을 컨트롤 루프라고 부른다. 현재 상태와 이상적인 상태가 다를 때 의도한 상태값으로 전환하도록, 계속 주기적으로 루프를 돈다는 의미가 된다.
가볍게 생각해보자. deployment를 생성한다고 가정했을 때, 우리가 해야 할 일은 다음 3가지로 요약될 것이다.
- deployment spec을 yaml 파일로 작성합니다.
- kubectl apply 명령어를 실행합니다.
- deployment 생성 요청이 kubernetes API 서버로 전달됩니다. ETCD에 새로운 deployment object가 생성됩니다.

앞서 컨트롤러라는 개념을 소개할 때, Yaml 파일 스펙에 정의된 상태와 현재 상태가 일치하는지 지속적으로 확인한다고 했다. deployment 컨트롤러는 deployment라고 하는 특정한 쿠버네티스 리소스 유형을 추적하여 클러스터의 상태를 관찰한다. 만약 일치하지 않는다고 하면 컨트롤러는 사전에 정의된 필요한 작업을 수행할 것이다.
커스텀 리소스 (Custom Resource) 는 기본 쿠버네티스 API의 extension으로서, 구조화된 데이터를 저장하고 반환하는 형태를 띄고 있다. 오퍼레이터 패턴에서는 이상적인 리소스 상태를 표시하게 된다. 다시 말해서, 우리가 희망하는 상태 스펙을 정의하고 컨트롤러에게 생성할 파드의 개수, 생성할 파드의 이미지 등의 정보에 대해 알려주는 것이다. 커스텀 리소스가 한 번 설치되면 파드와 같이 kubectl 명령어를 사용해서 오브젝트를 생성, 접근할 수 있게 된다.
다음은 PostgreSQL에서의 커스텀 리소스를 표현한 것이다.
# 출처: https://loft.sh/blog/extending-kubernetes-with-custom-resource-definitions-crds/
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: databaseconnections.crds.example.com
spec:
group: crds.example.com
scope: Namespaced
names:
plural: databaseconnections
singular: databaseconnection
kind: DatabaseConnection
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
engine:
type: string
enum:
- mysql
- postgres
replicaCount:
type: integer
minimum: 1
maximum: 10
defaultSchema:
type: string
rootUser:
type: string
rootPassword:
type: string
required:
- engine
- defaultSchema
- rootUser
- rootPassword만약 deployment spec 내에 정의된 이미지가 배포된 파드의 이미지가 다르거나, spec 내 정의된 파드 개수가 현재 배포된 replica 개수와 다른 경우가 있을 수 있다. 이 때 컨트롤러는 현재 상태와 스펙에 정의된 상태가 다르다고 판단하고 필요한 조치를 취하게 된다. 예를 들어 새로운 ReplicaSet을 생성하거나, 기존 ReplicaSet 내부에서 replicas value를 조정하거나, 새로운 파드 오브젝트를 생성하는 등 필요한 역할을 수행하여 최종적으로 스펙에 정의된 상태를 맞추어갈 것이다.
위의 PostgreSQL의 커스텀 리소스를 살펴보면 spec 필드 아래에 replicaCount의 범위를 명명한 것으로 볼 수 있다. CRD가 등록되면 kubectl을 통해서 오브젝트에 접근할 수 있는데 이 때 CR은 DatabaseConnection 타입이라고 할 수 있다. 여기서 DatabaseConnection 로 정의된 커스텀 리소스가 생성되거나 업데이트가 되면 DatabaseConnection를 감시하는 오퍼레이터는 해당 리소스를 계속 탐지하여 CRD에 정의된 스펙에 맞추어서 동작하고 있는 지를 확인한다.
커스텀 리소스와 config map의 차이
처음에 다소 헷갈렸던 개념이 Custom Resource와 Config Map의 차이였다. 쿠버네티스에서 ConfigMap은 설정이나 비밀 값을 저장하는 리소스에 가깝다고 보면 되는데, 굳이 말하면 환경 변수를 설정하는 값에 가깝다고 보면 된다. 저장할 수 있는 데이터의 형식이 정해져있지 않다는 점에서 어느 정도 자유도가 있고 따라서 API Key 같은 값을 지정하기에 용이하다고 보면 된다.
이와 달리 Custom Resource는 특정한 애플리케이션의 config data를 명시적으로 설정하는 데 사용된다고 보는 것이 맞다. 우리가 클러스터에서 희망하는 어떤 설정 값을 명시하고, 필드를 검증하는 데 사용되는 것이다. 따라서 외부에 공개할 수 있는 경우도 있고 그래서 OperatorHub 와 같은 사이트에 가면 공개된 CRD를 다운로드 받을 수 있다. 이 때 성숙도가 레벨 3 이상인 오퍼레이터가 실무에서 사용하기 적합하다고 알려져있다.

아직까지 필자가 오퍼레이터를 직접 개발한 적은 없지만 Operator Framework 나 kubebuilder, KUDO를 이용하여 직접 오퍼레이터를 개발할 수 있다고 한다.
MySQL Operator를 설치해보자
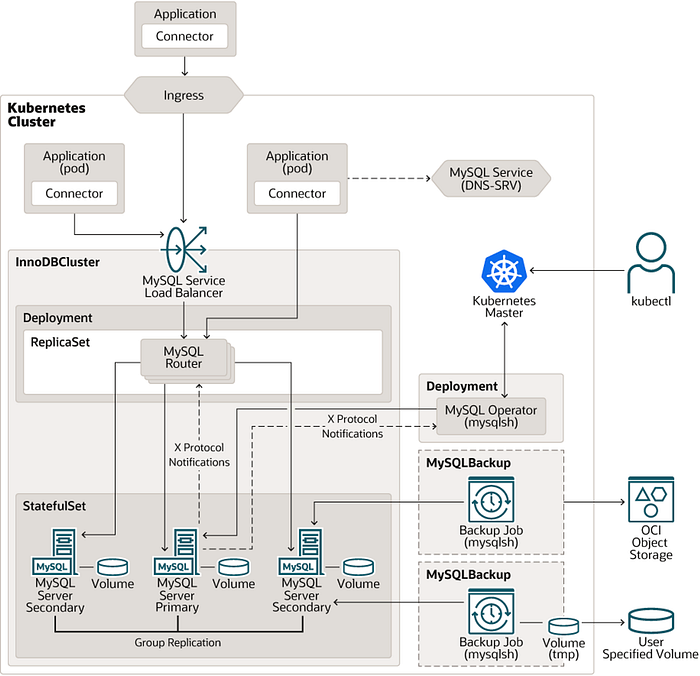
이번 DOIK 두 번째 시간에는 MySQL Operator for Kubernetes를 배포하는 시간을 가졌다. 실습 내용이 많았기 때문에 간단하게 정리하는 형태로 서술하고자 한다. MySQL InnoDB 클러스터를 관리하는데, 8.0.29 버전으로 GA 릴리즈된 버전이다. 내용을 찾아보면 MySQL Operator는 MySQL 서버와 라우터로 이루어진 InnoDB 클러스터를 관리한다고 언급한다. 여기서 MySQL 오퍼레이터가 추상화하여 관리하는 오브젝트는 MySQL InnoDB Cluster이다.
조금 더 Kubernetes 스럽게 말하자면, MySQL Operator는 InnoDB 클러스터라는 추상화된 Custom Resource로 MySQL 서버와 라우터들 간의 관계를 자동화하는 역할을 진행한다. 위의 다이어그램을 참고하면 MySQL Router가 보이는데, 이는 Deployment로 관리된다. MySQL 라우터는 MySQL 서버 중에서 작업을 실행할 서버를 고르는 Stateless 애플리케이션이다. 클러스터의 스케일에 따라 Deployment의 StatefulSets 개수를 조절하면서 수평적 확장이 가능하다는 특징이 있다.
MySQL 서버는 DB의 역할을 하는 서버 인스턴스의 그룹이라고 생각하면 되는데, Single-Primary 모드와 Multi-Primary 모드 중 하나를 선택할 수 있다. 특히 후자의 경우에는 Group Replication 복제 방식을 사용하여 양방향 복제를 수행할 수 있다는 특징을 가진다. 이 외에도 MySQL Operator가 있고 여기서는 InnoDBCluster 및 MySQLBackup 등의 Custom Resource로 백업 등을 추상화하여 동작시킬 수 있다.
다음과 같이 설치하여 보자.
helm install mysql-operator mysql-operator/mysql-operator - namespace mysql-operator - create-namespace - version
2.0.12 helm get manifest mysql-operator -n mysql-operator
kubectl get deploy,pod -n mysql-operator

Helm InnoDB Cluster에 설치할 때 파라미터 파일은 이렇다.
# 파라미터 파일 생성 cat <<EOT> mycnf-values.yaml credentials: root: password: sakila serverConfig: mycnf: | [mysqld] max_connections=300 default_authentication_plugin=mysql_native_password tls: useSelfSigned: true EOT다음과 같이 설치해줄 수 있다. 차트 설치의 기본 값은 서버 인스턴스 파드가 3개, 라우터 인스턴스 파드가 1개이다.
helm install mycluster mysql-operator/mysql-innodbcluster - namespace mysql-cluster - version 2.0.12 -f mycnf-values.yaml - create-namespace


InnoDB Cluster 초기 설정을 확인하기 위하여 configmap을 살펴보자. 현재 우리가 배포한 버전에는 group replication 모드가 활성화되어 있다.
kubectl describe configmap -n mysql-cluster mycluster-initconf
[mysqld] log_bin=mycluster enforce_gtid_consistency=ON gtid_mode=ON # 그룹 복제 모드 사용을 위해서 GTID 활성화 relay_log_info_repository=TABLE # 복제 메타데이터는 데이터 일관성을 위해 릴레이로그를 파일이 아닌 테이블에 저장 skip_slave_start=1
99-extra.cnf: - - # Additional user configurations taken from spec.mycnf in InnoDBCluster. # Do not edit directly. [mysqld] max_connections=300 # max_connections default 기본값은 151 default_authentication_plugin=mysql_native_password마찬가지로 서버 인스턴스 확인을 위해 stateful set을 체크해보자. 3개의 노드에 각각 파드가 생성되어 있는지 확인하고 사이드카 컨테이너를 배포한다.
kubectl get sts -n mysql-cluster; echo; kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=database -owide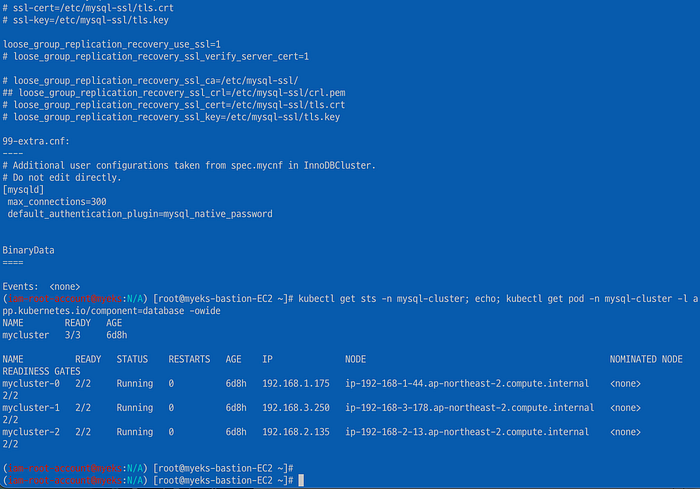
라우터 인스턴스 접속을 통해 max_connections 설정 값을 확인해볼 수 있다.
## 라우터인스턴스(디플로이먼트) 확인 : 1대의 파드 생성 확인 kubectl get deploy -n mysql-cluster;kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=router
## 라우터인스턴스 접속을 위한 서비스(ClusterIP) 확인 kubectl get svc,ep -n mysql-cluster mycluster
# max_connections 설정 값 확인 : MySQL 라우터를 통한 MySQL 파드 접속 >> Helm 차트 설치 시 파라미터러 기본값(151 -> 300)을 변경함 MIC=mycluster.mysql-cluster.svc.cluster.local echo "export MIC=mycluster.mysql-cluster.svc.cluster.local" >> /etc/profile kubectl exec -it -n mysql-operator deploy/mysql-operator - mysqlsh mysqlx://root@$MIC - password=sakila - sqlx - execute="SHOW VARIABLES LIKE 'max_connections';"
Headless 서비스 주소로 개별의 MySQL 서버 파드로 접속하여 DNS 쿼리 및 MySQL 파드에 접속을 해볼 수 있다.
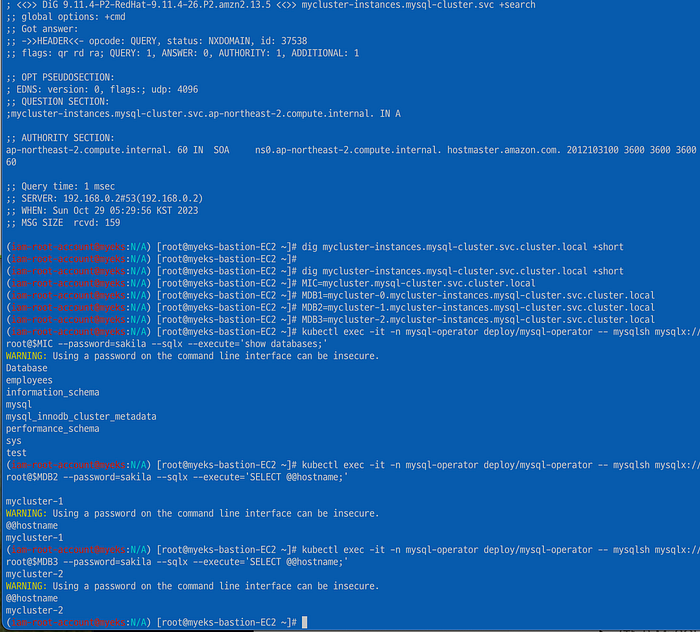
dig mycluster-instances.mysql-cluster.svc +search dig mycluster-instances.mysql-cluster.svc.cluster.local +short
MIC=mycluster.mysql-cluster.svc.cluster.local MDB1=mycluster-0.mycluster-instances.mysql-cluster.svc.cluster.local MDB2=mycluster-1.mycluster-instances.mysql-cluster.svc.cluster.local MDB3=mycluster-2.mycluster-instances.mysql-cluster.svc.cluster.local
kubectl exec -it -n mysql-operator deploy/mysql-operator - mysqlsh mysqlx://root@$MIC - password=sakila - sqlx - execute='show databases;'헤드리스 서비스를 통해 내가 원하는 파드에 접속할 수 있다.
* 샘플로 대용량 데이터베이스 주입을 해 보자. 실험에 사용한 것은 30만명 직원의 400만 개의 레코드로 구성되어 있고 6개의 테이블과 160MB 데이터를 넣었다.
https://github.com/datacharmer/test_db
# 샘플 데이터베이스 git clone git clone https://github.com/datacharmer/test_db && cd test_db/
# 마스터 노드에 mariadb-client 툴 설치 yum install mariadb -y mysql -h127.0.0.1 -P3306 -uroot -psakila -e "SELECT @@hostname;" # To import the data into your MySQL instance, load the data through the mysql command-line tool: 1분 10초 정도 소요 mysql -h127.0.0.1 -P3306 -uroot -psakila -t < employees.sql # 확인 mysql -h127.0.0.1 -P3306 -uroot -psakila -e "SHOW DATABASES;" mysql -h127.0.0.1 -P3306 -uroot -psakila -e "USE employees;SELECT * FROM employees;" mysql -h127.0.0.1 -P3306 -uroot -psakila -e "USE employees;SELECT * FROM employees LIMIT 10;"
# 각각 헤드리스 서비스 주소로 각각의 mysql 파드로 접속하여 데이터 조회 확인 : 대용량 데이터 복제가 잘 되었는지 확인해보기! kubectl exec -it -n mysql-operator deploy/mysql-operator - mysqlsh mysqlx://root@$MDB1 - password=sakila - sqlx - execute="USE employees;SELECT * FROM employees LIMIT 5;" kubectl exec -it -n mysql-operator deploy/mysql-operator - mysqlsh mysqlx://root@$MDB2 - password=sakila - sqlx - execute="USE employees;SELECT * FROM employees LIMIT 5;" kubectl exec -it -n mysql-operator deploy/mysql-operator - mysqlsh mysqlx://root@$MDB3 - password=sakila - sqlx - execute="USE employees;SELECT * FROM employees LIMIT 5;"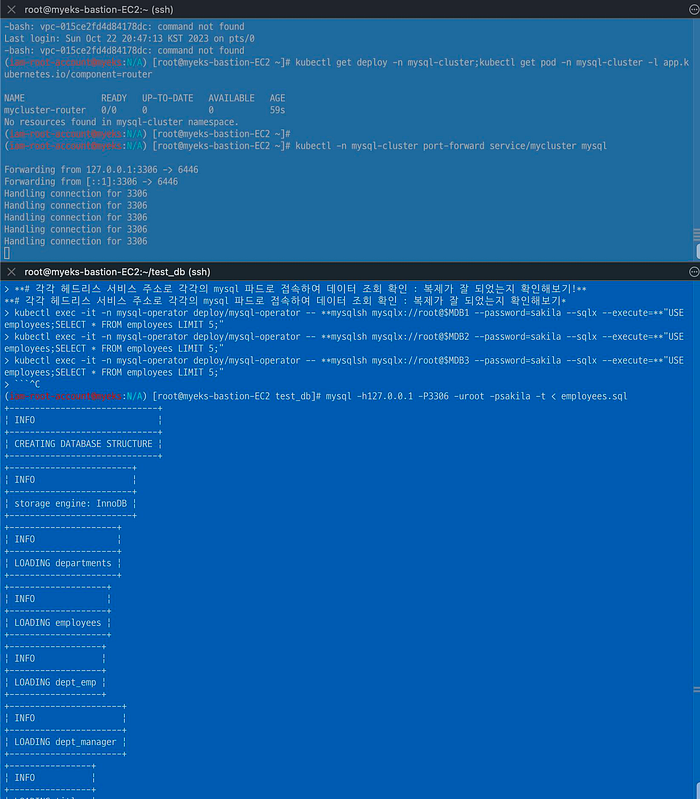
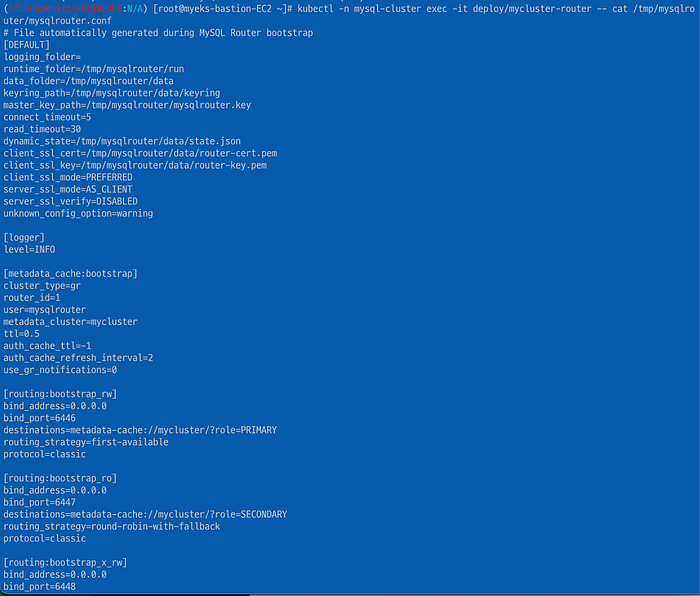
특히 Router는 사용자의 요청을 InnoDB 클러스터로 부하 분산을 하는데, 쓰기 RW 요청과 읽기 RO 요청을 설정에 따라 MySQL Pod로 rerouting을 하게 된다. InnoDB는 참고로 default 설정으로 primary 1대와 secondary 인스턴스 2개로 이루어져 있다. 아래 Router 설정에서 주목할 부분은 RW 퐅트와 RO 포트가 분리되어 있다는 것이고 destinations로 Role이 Primary이냐 Secondary 이냐의 차이가 보인다. 다시 말해서, client가 router에 RO(6446 port) 또는 RW (6447) 포트로 요청을 보내면, cluster에서 RW 라우팅 정책은 primary RW 노드로 요청이 이루어지고, 그 외 RO 라우팅 정책은 라운드 로빈 방식으로 secondary RO 노드에 요청이 이루어지게 된다.
kubectl -n mysql-cluster exec -it deploy/mycluster-router - cat /tmp/mysqlrouter/mysqlrouter.confClient가 Router에 요청할 때 6447 RW와 RO 포트를 설정하지 않으면 RW 라우팅 규칙이 우선적으로 적용되어 Primary MySQL Pod으로 접근하게 된다. 기본 라우팅 정책은 first-available이 되고 이는 RW일 떄 primary로 요청한다는 뜻이다. 그 외에 RO는 round robin 방식으로 요청하게 된다.
Primary 파드는 MySQL 라우터 정책이 first-available 이라서 무조건 하나의 고정 멤버로만 접근이 가능하다.
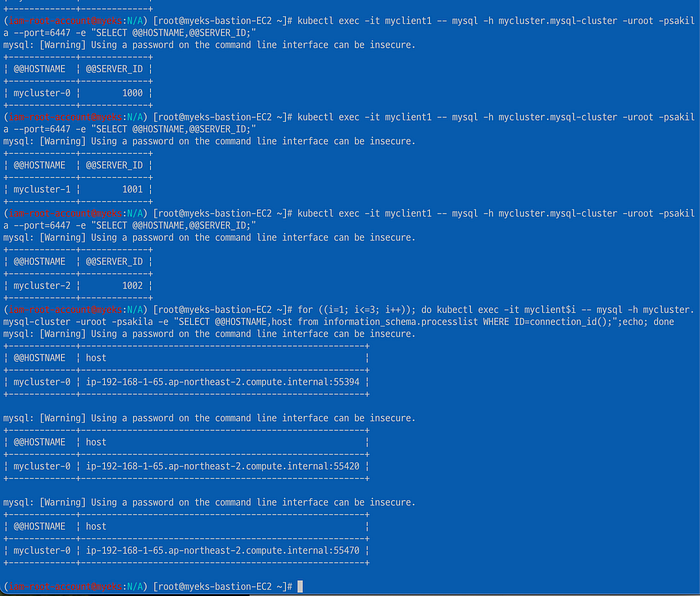
Secondary 파드로 이루어진 6447로 접근한 것이고 3초 간격에 접근한다.
MySQL의 mariadb client에서 Multi-Primary 모드로 전환해보자.
SELECT group_replication_switch_to_multi_primary_mode();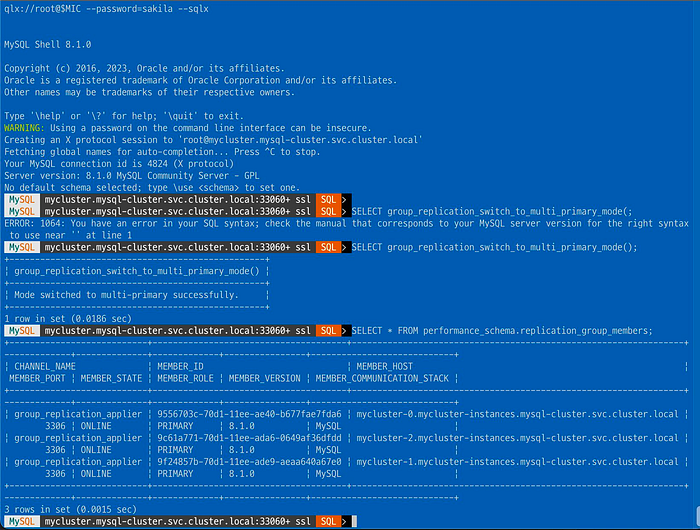
모든 파드가 Primary라는 것을 알 수 있다.
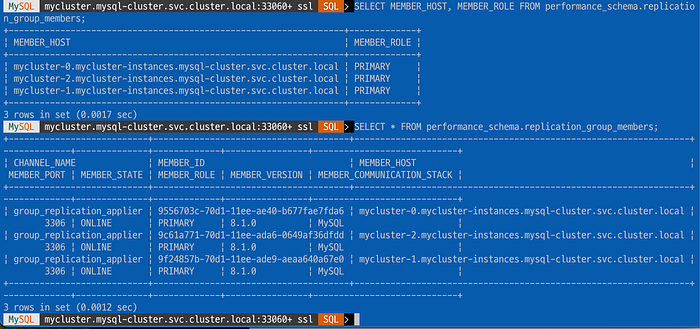
다시 Single-Primary 모드로 돌아올 수도 있다.
SELECT group_replication_switch_to_single_primary_mode();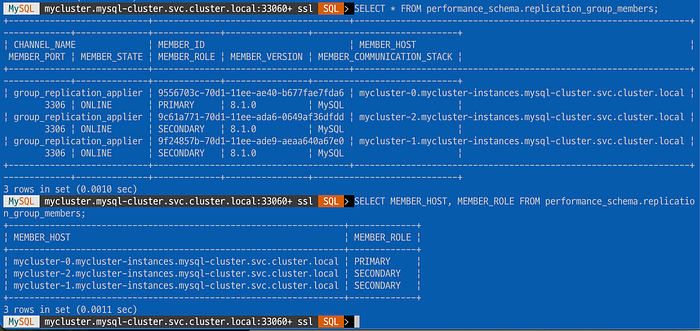
만약에 반복적으로 데이터를 Insert하고 MySQL에 복제가 잘 되었는지 확인하려면 어떻게 해야 할까? 반복적으로 추가하고 조회해보자.
for ((i=3; i<=100; i++)); do kubectl exec -it myclient1 - mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME;USE test;INSERT INTO t1 VALUES ($i, 'Luis$i');";echo; done kubectl exec -it myclient1 - mysql -h mycluster.mysql-cluster -uroot -psakila -e "USE test;SELECT * FROM t1;"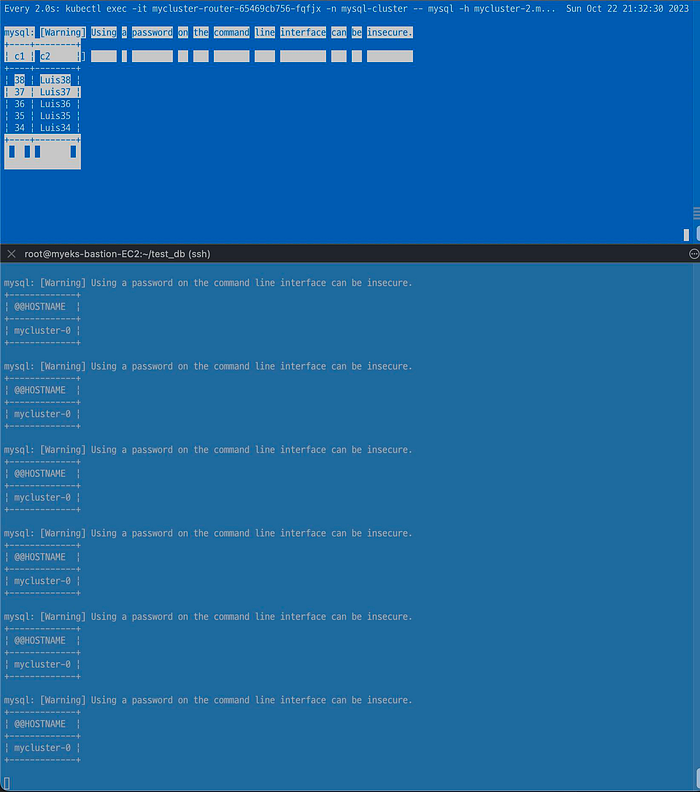
Primary에 먼저 쓰고 Secondary는 실시간으로 복제를 하는 것을 아래 터미널을 켜서 관찰할 수 있다.
watch -d "kubectl exec -it myclient1 - mysql -h mycluster-0.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'" watch -d "kubectl exec -it myclient2 - mysql -h mycluster-1.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'" watch -d "kubectl exec -it myclient3 - mysql -h mycluster-2.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'"당연히 Secondary 서버 파드에는 INSERT가 되지 않고 그 이유는 ` — super-read-only option` 때문인 것이다.

Scale 테스트를 해 보자.

helm repo를 update하고 기존의 값을 재사용하여 서버 파드 인스턴스를 2대 추가해본다. 데이터 복제 등으로 시간이 걸릴 수 있으니 인내심을 가지고 기다려본다.
helm upgrade mycluster mysql-operator/mysql-innodbcluster - reuse-values - set serverInstances=5 - namespace mysql-cluster
서버 파드 말고도 라우터 파드도 3개 증가시킬 수 있다.
helm upgrade mycluster mysql-operator/mysql-innodbcluster - reuse-values - set routerInstances=3 - namespace mysql-cluster추가를 진행하고 다음 명령어를 통해 적용된 값을 확인할 수 있다.
kubectl get innodbclusters -n mysql-clusterMySQL 백업과 복구
Backup 설정 정보를 확인해보자. 5분마다 스케줄 백업이 실행된다.
kubectl describe innodbcluster -n mysql-cluster | grep Spec: -A12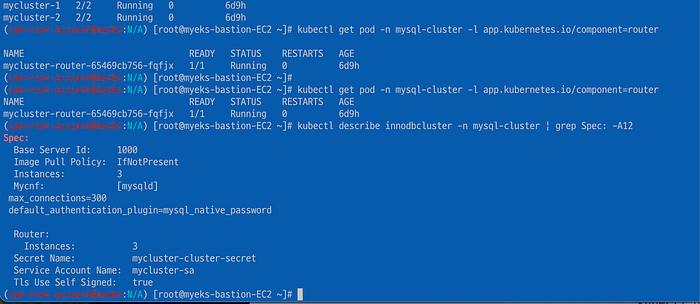
k8s 시크릿키를 다시 한번 설정해본다.
kubectl create secret generic mypwds \
- from-literal=rootUser=root \
- from-literal=rootHost=% \
- from-literal=rootPassword="sakila"myexample_pvc.yaml 이라는 이름으로 PVC를 설정해본다.
# pvc.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: myexample-pv
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /tmp
- -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myexample-pvc
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gikubectl 명령어로 PVC를 apply 해준다.
values.yaml이라는 CRD를 만들어 mysql-operator를 upgrade한다.
# values.yaml
backupProfiles:
- name: myfancyprofile
dumpInstance:
dumpOptions:
excludeTables: "[world.country]"
storage:
persistentVolumeClaim:
claimName: myexample-pvc
backupSchedules:
- name: mygreatschedule
schedule: "0 0 * * *"
backupProfileName: myfancyprofile
enabled: true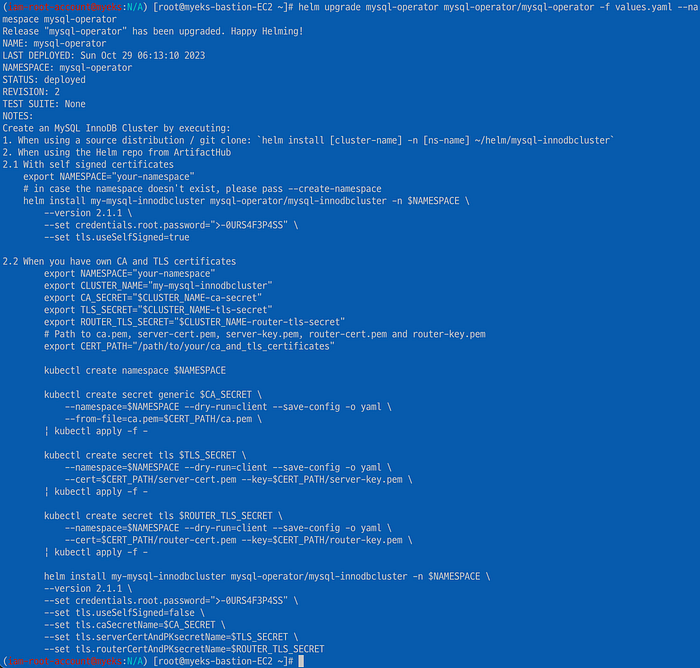
작업을 진행하게 되면 최소 5분 뒤에 결과를 확인할 수 있게 된다. 백업으로 사용되는 PVC를 확인하면 백업 이전에는 Pending 상태였다가 단 한 번이라도 백업에 사용되면 Bound로 변경되는 것을 확인할 수 있었다.

Remark
오퍼레이터를 사용하기 위해서는 쿠버네티스에 대한 이해보다는 애플리케이션 아키텍처와 동작을 이해하는 것이 더 중요하다고 한다. 예를 들어 프로메테우스 서버는 왜 필요하지? 모니터링은 왜 필요하지? 이런 고민을 가장 먼저 해야 한다. 쿠버네티스는 결국 테크닉인 것이기 때문에 SRE 고민을 할 수 있는 작업자의 도메인 지식이 가장 중요하다고 말할 수 있다.
뿐만 아니라 이번 워드프레스 실습에서도 나온 이야기이지만 특정한 노드를 drain 시켜야 할 일은 분명히 있다. 쿠버네티스 클러스터 업그레이드 때문에 노드 간의 관계를 고려하여 순차적으로 재기동을 해야하거나, 아니면 CPU나 메모리 단에서 인프라 레벨에 문제가 있어 노드가 불안정하게 작동할 경우가 이에 해당할 수 있겠다. Standard 서비스의 경우에는 현재 사용 가능한 파드로 로드 밸런싱이 되지만 Headless 서비스의 경우에는 직접 개별 파드에 접근이 가능한 형태이므로 파드가 내려갈 경우 downtime이 발생할 여지가 있다. 따라서 재시도나 서킷 브레이커와 같은 패턴을 세심하게 구성할 필요가 있다고 느껴진다. 혹은 istio로 대표되는 서비스 메시처럼 서비스 대 서비스 통신에 있어서 sidecar proxy를 별도로 도입하는 것도 방법이겠다.
