CloudNativePG 사용해 보다
The Kubernetes-powered PostgreSQL

PostgreSQL은 세계 4위의 RDBMS이고, 트랜잭션과 인덱싱 등 데이터베이스 기능과 클러스터 등 안정성을 위한 기능을 제공하고 있다. 특히 최근에 등장하는 Vector DB Extension도 추가되는 등 풍부한 생태계를 갖추고 있는 데이터베이스라고 할 수 있다. 주로 오픈소스 RDB를 사용할 때는 MySQL 또는 PostgreSQL을 사용하는데, MySQL의 사용량이 조금 더 높지만 생태계의 풍부함은 PostgreSQL을 따라오지 못하는 것 같다. 심지어 All You Need is PostgreSQL이라고 하는 아주 공격적인 아티클도 있다.
만약 쿠버네티스 상에서 데이터베이스를 운영하고 싶다면 Operator의 힘을 빌리면 매우 도움이 될 것이다. Operator는 지난 시간에 알아본 것과 같이 Deployment/Service/Pod 등 predefined 리소스를 제외하고 새로운 리소스를 정의하여 등록할 수 있다. 사용자가 커스텀하게 정의한 애플리케이션 리소스를 Operator라고 하며, 주로 Stateless Application에 대한 Deployment 보다는 Stateful Application에서 DB와 같은 리소스에서 사용된다. 예를 들어 DB 클러스터는 주기적으로 백업을 자동으로 한다거나, 마스터 노드가 Down 되었을 때 Election 작업을 통해 새로운 마스터 노드를 선출한다거나 하는 일이 있겠다.
PostgreSQL은 CloudNativePG라는 Operator가 있는데, 성숙도 레벨은 Level 5라서 높은 성숙도를 자랑하기 때문에 안심하고 사용할 수 있다. 물론 아래에서 구현을 해보면 알 수 있겠지만 CloudNativePG는 StatefulSet를 사용하지 않고 Operator를 커스텀하게 개발하여 DB Cluster를 만드는 경우를 지원하기 때문에 인스턴스가 Pod로 띄워진 것을 확인할 수 있다. 특히, PV에 저장된 데이터 보존과 재 연결, 자동 스위칭을 할 때 Primary / Standbys를 순서 무관하게 구분해야 하는 요구 사항, 재시작을 요구하는 PostgreSQL config 설정 변경 등을 지원해야 하는데 기존의 StatefulSets를 사용하지 않기 때문이다.

https://www.alibabacloud.com/blog/postgresql-haproxy-proxy-for-ha-and-load-balance_597618
CloudNativePG의 클러스터는 세 가지 인스턴스로 나뉘어진다. 하나는 RW인데, 이는 쓰기를 위한 Primary DB 인스턴스 접근이다. INSERT, UPDATE, DELETE가 실행되는 것이다. R은 읽기를 위한 임의의 DB 인스턴스를 접근하는 것이다. R 인스턴스는 primary나 standby 인스턴스 모두가 될 수 있고 HA를 위해 위에 보이는 것처럼 여러 읽기 전용 인스턴스가 배포될 수 있다. 마지막으로 RO는 읽기를 위한 Standby DB 인스턴스에 접근하는 것이다. Primary 인스턴스의 데이터를 동기화받고, 데이터의 읽기 요청만 처리하게 된다. Replication을 통해 Primary 인스턴스와 동기화되고 시스템의 읽기 용량을 확장하는 데 사용된다.

Read-Write Workloads 는 Application이 RW 요청에 대해 Primary Instance로 접근하여 쿼리를 수행하게 된다. 기본적으로 Primary 노드는 read-write workloads를 전제하고, replica는 read-only query만 처리한다. Primary 노드가 실패하게 되면 선출을 통해 Replica 노드가 Primary 노드가 될 수 있다. 이 외에도 Backup operation이 이루어질 수 있다.
Read-only 요청은 Standby 인스턴스로 Round Robin 방식을 통해 전달된다. RO와 R(only가 아닙니다) 요청에 대해 Standby Instance로 접근하여 쿼리를 수행하게 된다. 부하분산 기준은 라운드 로빈이다.

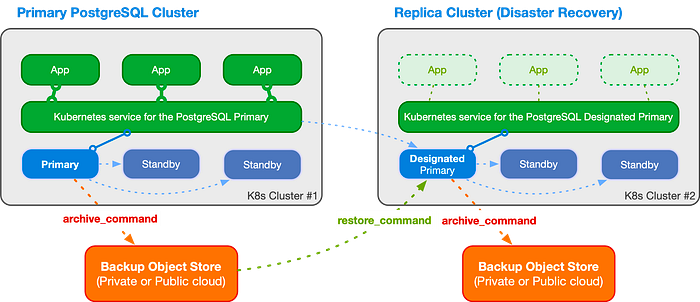
CloudNativePG 끼리 다수의 Kubernetes Cluster에 배포되어도 동기화가 지원된다. 멀티 클러스터 데이터베이스 환경에서도 전 세계 복구 지점 목표를 축소해야 하고 (이를 RPO) 라고 부른다, 그리고 글로벌 복구 시간 목표 (RTO) 를 축소해야 한다.
이러한 두 가지 요구사항을 만족하기 위해서 Replica Cluster라는 개녕믈 이용한다. Replica Cluster에 Designated Primary 라는 개념이 있는데 사전에 Primary가 될 노드를 사전에 지정하는 것이다. Primary 클러스터의 Primary Replica로 동작하면서 이 때 클라우드의 S3 같은 Backup Object를 통해 Primary에서 Replica로 복제함으로서 고가용성을 확보하고 재해복구 시간을 축소할 수 있는 것이다.
설치 가이드
- 먼저 Operator를 설치하고 Cluster를 구축해야 한다.
- 우리는 Operator Lifecycle Manager 라는 것을 이용해서 설치를 할 것인데, 줄여서 OLM이라고 부른다. 말 그대로 Operator를 관리하는 매니저인데 업데이트하고 백업하고 스케일링하는 일을 한다.
- 쿠버네티스에 Application의 모든 관리를 맡기는 것이 불가능하기 때문에 사용하는 패턴이라고 한다.
- OLM은 Custom Resource인데 YAML Template이 있어 버전이나 클러스터의 인스턴스 개수 등을 조절할 수 있다.
# 클러스터에 실행중인 Operator를 관리하기 위한 Operator Lifecycle Manager(OLM) 을 설치합니다.
# olm namespace에 설치됩니다.$ curl -sL https://github.com/operator-framework/operator-lifecycle-manager/releases/download/v0.25.0/install.sh | bash -s v0.25.0
# 설치결과 확인
$ kubectl get ns $ kubectl get all -n olm
$ kubectl get-all -n olm
$ kubectl get all -n operators
$ kubectl get-all -n operators | grep -v packagemanifest
# CloudNativePG Operator를 설치하고, operator namespace에 설치한다.
$ curl -s -O https://operatorhub.io/install/cloudnative-pg.yaml
$ cat cloudnative-pg.yaml | yh
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: my-cloudnative-pg
namespace: operators
spec:
channel: stable-v1
name: cloudnative-pg
source: operatorhubio-catalog
sourceNamespace: olm
$ kubectl create -f cloudnative-pg.yaml
$ kubectl get all -n operators
…
$ kubectl get-all -n operators | grep -v packagemanifest
…
$ kubectl get crd | grep cnpg
# 설치한 cluster의 정보를 확인한다.
$ kubectl get clusterserviceversions -n operators
```- 이제 CloudNativePG Cluster를 설치할 것인데, postgres 버전은 15.3이다.
- 구성: Primary 1대, Standby 2대, pg_hba (보안): all_open
- bootstrap 설정: database (app) / encoding (UTF-8) / owner (app : user)
- `mycluster1.yaml` 파일 아래가 있고 이를 이용해서 PG Cluster를 구성한다.
- 먼저 각 인스턴스 별로 initdb pod가 먼저 생성되어 구성되고, 이후에 postgres cluster에 인스턴스가 Join 되는 형태로 구현된다. 설치되는 파드 순서를 확인해보면 좋다.
cat <<EOT> mycluster1.yaml
# Example of PostgreSQL cluster
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: mycluster
spec:
imageName: ghcr.io/cloudnative-pg/postgresql:15.3
instances: 3
storage:
size: 3Gi
postgresql:
parameters:
max_worker_processes: "40"
timezone: "Asia/Seoul"
pg_hba:
- host all postgres all trust
primaryUpdateStrategy: unsupervised
enableSuperuserAccess: true
bootstrap:
initdb:
database: app
encoding: UTF8
localeCType: C
localeCollate: C
owner: app
monitoring:
enablePodMonitor: true
EOT
$ kubectl get all을 하면 R/RO/RW 클러스터 3개가 생성된 것을 확인할 수 있다.- CNPG (https://cloudnative-pg.io/documentation/1.20/kubectl-plugin/) 라고 불리는 kubectl 플러그인을 구성한 플러그인의 상세 정보를 확인하기 용이하다. 다음과 같은 커멘드를 이용하면 config 설정이 잘 적용된 것을 확인할 수 있다.
```
$ kubectl cnpg status mycluster - verbose
```
* 인스턴스가 Pod임을 확인할 수 있다.
```
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/mycluster-1 1/1 Running 0 9m21s
pod/mycluster-2 1/1 Running 0 8m25s
pod/mycluster-3 1/1 Running 0 7m37s
```
* PGBouncer라는 플러그인을 이용하면 R/RO/RW Instance에 클라이언트가 접속하기 위해서 필요한 별도의 레이어를 둘 수 있다. 특히 CloudNativePG에 접근하기 위하여 커넥션 풀을 사전에 만들어두고, 클라이언트 요청이 들어오면 커넥션 풀에서 재사용하는 것이 가능하게 된다. 이 외에도 인증이나 모니터링 책임을 가져갈 수도 있다.
* 기본적으로 PG cluster는 비동기 복제 옵션을 사용하는데 (https://eoriented.github.io/post/replication-2/) PgBouncer는 동기 복제 옵션을 사용한다. 이 외에도 Promethues 로깅을 할 수 있는데, 외부에서 PgBouncer에 접속하려면 NLB expose를 해 주어야 한다.
![[Pasted image 20231105021238.png]]
```
cat <<EOT> pooler.yaml
apiVersion: postgresql.cnpg.io/v1
kind: Pooler
metadata: name: pooler-rw
spec:
cluster:
name: mycluster # CloudNativePG cluster 이름
instances: 3 # instance 개수
type: rw # rw 앞단에 생성
pgbouncer:
poolMode: session
parameters:
max_client_conn: "1000" # max client connection 지정
default_pool_size: "10" # pool size
EOT
$ kubectl apply -f pooler.yaml && kubectl get pod -w
```
![[Pasted image 20231105015936.png]]
### CloudNativePG의 사용
* CloudNativePG를 사용하기 위해서는 같은 클러스터 내부에서 접근하는 경우랑 외부 클라이언트에서 접근하는 경우 크게 2가지로 나눌 수 있다.
* 먼저 내부에서 접근하는 아래 스크립트를 보면 User 별로 자격 증명을 생성하고 계정명과 암호를 secret에서 추출한 다음 이를 변수로 지정하여 myclient 파드를 3개 배포하는 형태로 되어 있다.
```
# 2개의 자격 증명이 저장된 secret 확인
$ kubectl get secret -l cnpg.io/cluster=mycluster
NAME TYPE DATA AGE
mycluster-app kubernetes.io/basic-auth 3 109m
mycluster-superuser kubernetes.io/basic-auth 3 109m
# superuser 계정명
$ kubectl get secrets mycluster-superuser -o jsonpath={.data.username} | base64 -d ;echo postgres
# superuser 계정 암호
$ kubectl get secrets mycluster-superuser -o jsonpath={.data.password} | base64 -d ;echo UUTWc0Apwp8i0BbXd06ja6B4LURuFPAsuSlV6XKzoebMqEksQdANdNF0cPlQxio0 kubectl get secrets mycluster-superuser -o jsonpath={.data.pgpass} | base64 -d mycluster-rw:5432:*:postgres:TOk00xrh8kuT1uJJpMOuwotWag3dsFieXIuZwzn04OZYoyA8GPdza2xu8OgiUMTd
# app 계정명
$ kubectl get secrets mycluster-app -o jsonpath={.data.username} | base64 -d ;echo app
# app 계정 암호
$ kubectl get secrets mycluster-app -o jsonpath={.data.password} | base64 -d ;echo nLDgzc1ZGTT5BC1NV8Rjw1bfO7yuwoATg01WgjpOyTxyUyckrmLVHbQ3oI4IJUYp
# app 계정 암호 변수 지정
$ AUSERPW=$(kubectl get secrets mycluster-app -o jsonpath={.data.password} | base64 -d)
# myclient 파드 3대 배포 : envsubst 활용
## PODNAME=myclient1 VERSION=15.3.0 envsubst < myclient.yaml | kubectl apply -f -
curl -s https://raw.githubusercontent.com/gasida/DOIK/main/5/myclient-new.yaml -o myclient.yaml for ((i=1; i<=3; i++)); do PODNAME=myclient$i VERSION=15.3.0 envsubst < myclient.yaml | kubectl apply -f - ; done
```
* 이렇게 배포가 되었다면, 연결 정보나 데이터베이스 조회, 타임 존 등을 확인하여 설정값에 대한 검증을 할 수 있다.
```bash
$ kubectl exec -it myclient1 - psql -U postgres -h mycluster-rw -p 5432 - variable=HISTFILE=/tmp/.psql_history
postgres=# \conninfo
You are connected to database "postgres" as user "postgres" on host "mycluster-rw" (address "10.100.114.165") at port "5432".
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
# password를 직접. 입력해 줍니다.
$ kubectl exec -it myclient1 - psql -U app -h mycluster-rw -p 5432 -d app Password for user app: psql (15.3) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help.
app=> \conninfo
You are connected to database "app" as user "app" on host "mycluster-rw" (address "10.100.114.165") at port "5432". SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) app=> \l- EKS 외부에서 접근해야 한다면, NLB를 사용해서 TCP/UDP를 사용할 수 있도록 구성한 다음에 이를 이용해서 CloudNativePG를 활용해야 한다.
# postgresql psql 툴 설치
$ yum install postgresql -y
# Service(LoadBalancer)로 외부 노출 설정 : 3~5분 정도 대기 후 아래 접속 시도
$ kubectl get svc,ep mycluster-rw
# patch 명령어로 service type을 Loadbalancer로 변경하여 LB 프로비저닝 $ kubectl patch svc mycluster-rw -p '{"spec":{"type":"LoadBalancer"}}'
# ExternalDNS Controller를 이용해서 Route53 Domain을 이용, dns이름 생성
$ kubectl annotate service mycluster-rw "external-dns.alpha.kubernetes.io/hostname=psql.$MyDomain"
# psql로 접속
psql -U postgres -h psql.$MyDomain - - - - - - - - - - - - - - - - - app=> \conninfo app=> \l app=> \q - - - - - - - - - - - - - - - - -- 이렇게 접속한 서비스에 대하여 각 서비스에 요청이 들어왔을 때 어떻게 트래픽이 분산되는 지 테스트할 수 있다. RW 서비스와 RO 서비스, 그리고 R 서비스에 순차적으로 요청을 보냈을 때 어느 파드로 요청이 가는지를 확인하면 된다. RW (쓰기) 서비스에는 primary 1대에 요청이 들어가고, 그 다음에는 RO (읽기만 필요하고 트래픽이 많아진다면) 서비스에 요청을 보내 standby 파드로 요청이 분산되고, 마지막으로 R 서비스에는 전체 파드로 요청이 부하분산 되는 것을 확인할 수 있다.
$ for i in {1..30}; do kubectl exec -it myclient1 - psql -U postgres -h mycluster-rw -p 5432 -c "select inet_server_addr();"; done | sort | uniq -c | sort -nr | grep 192 30 x.x.1.250
$ for i in {1..30}; do kubectl exec -it myclient1 - psql -U postgres -h mycluster-ro -p 5432 -c "select inet_server_addr();"; done | sort | uniq -c | sort -nr | grep 192 17 x.x.2.202 13 x.x.3.48
$ for i in {1..30}; do kubectl exec -it myclient1 - psql -U postgres -h mycluster-r -p 5432 -c "select inet_server_addr();"; done | sort | uniq -c | sort -nr | grep 192 12 x.x.2.202 10 x.x.3.48 8 x.x.1.250장애 스터디를 하는 방법은 다음과 같다. 테스트용 테이블 `t1` 을 하나 생성해두고 해당 테이블에 데이터를 밀어넣은 다음, myclient2 pod을 설치하여 모니터링한다. 만약 Primary Pod에서 장애가 일어나고 있을 때, Write는 primary pod에서 발생하고 있으므로 write 문제라고 이해할 수 있으며, primary pod를 cnpg를 이용하여 먼저 찾아야 한다. 우리는 Primary Pod의 파드와 PVC를 삭제하는 것으로 장애를 테스트한다.
# 프라이머리 파드 정보 확인
# Primary Pod는 mycluster-1
$ kubectl cnpg status mycluster
Instances status Name Database Size Current LSN Replication role Status QoS Manager Version Node - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
mycluster-1 29 MB 0/6000060 Primary OK BestEffort 1.21.0 ip-x-x-3–89.ap-northeast-2.compute.internal mycluster-2 29 MB 0/6000060 Standby (async) OK BestEffort 1.21.0 ip-x-x-3–17.ap-northeast-2.compute.internal mycluster-3 29 MB 0/6000060 Standby (async) OK BestEffort 1.21.0 ip-x-x-1–113.ap-northeast-2.compute.internal- 장애 발생 시점에서 Insert가 순간적으로 이루어지지 않다가 다시 기존의 `mycluster-2` 가 Primary로 승격 되면서 Insert가 정상적으로 진행됨을 확인할 수 있을 것이다. 대신 `mycluster-4` 가 새로이 생성되면서 Replica 개수를 3개로 유지할 수 있다.
* 참고로 이 외에도 `kubectl cnpg promote mycluster mycluster-3` 명령어를 이용하면 수동으로 Primary Pod 인스턴스를 standby pod과 바꾸는 것이 가능합니다.
$ kubectl cnpg status mycluster
NAME READY STATUS RESTARTS AGE
mycluster-2 1/1 Running 0
mycluster-3 1/1 Running 0
mycluster-4 0/1 Init:0/1 0
mycluster-4-join-jnf9x 0/1 Completed 0 62s
$ kubectl exec -it myclient3 - psql -U postgres -h mycluster-rw -p 5432 -c "select inet_server_addr();"
inet_server_addr
- - - - - - - - -- Primary Pod가 배포되어 있는 노드 자체에 만약 장애 상황이 발생한다면, 예를 들어 우리가 직접 노드를 drain 시키면서 기존의 pimary pod에서 담당되던 insert event는 끊긴다. 하지만 읽기 작업은 여전히 standby pod에서 진행할 수 있으므로 크게 문제가 되지 않는다.
$ NODE=<NodeName>
# usecase
$ NODE=ip-x-x-3–17.ap-northeast-2.compute.internal
$ kubectl drain $NODE - delete-emptydir-data - force - ignore-daemonsets && kubectl get node -w- 그런데 기존 Primary Pod는 Pending 상태로 남게 된다. 그 이유를 살펴보면 EKS 환경에서 gp2라는 StorageClass를 사용하는데 이 과정에서 AWS EBS는 하나의 EC2 Instance에만 마운트가 될 수 있다. 노드 1번의 인스턴스가 있고 해당 인스턴스에 1번 PV/EBS가 이미 할당되었는데, 해당 PV를 1번 PVC가 요청하고 있는데 1번 PVC를 특정 Pod가 마운트하고 있으면, 해당 Pod는 다른 Node로 provisioning할 수 없게 된다.
- 에러 메시지: 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
Scale Tests
- 기존의 인스턴스 3대 구성에서 5대로 증가시킨다. 기본적으로 Join Pod가 생성되었다가 Complete가 되면서 실제 Pod Instance를 cluster에 JOIN하게 된다. 최종적인 확인은 CNPG 로 진행하기를 바란다.
$ kubectl patch cluster mycluster - type=merge -p '{"spec":{"instances":5}}' && kubectl get pod -l postgresql=mycluster -w
mycluster-4-join-hs9ng 0/1 Completed 0 18s
$ kubectl cnpg status mycluster- Pod에 부하분산 되는 기준은 위에도 설명하였다시피 Robin Round에 근간하고, Readiness Probe를 통과해야 다음 목적지로 트래픽이 이동되므로 Probe를 이용하여 특정한 클라이언트의 요청에 대한 처리 순서를 지정하거나 동일한 파드에게만 가도록 작업하는 방향 또는 Session Affinity (sticky session) 를 활용하여 특정 클라이언트 요청이 특정한 파드에만 가도록 구현할 수도 있다.
Reference
* https://www.enterprisedb.com/blog/biganimal-introducing-cloud-native-postgresql-plugin-kubectl
* https://cloudnative-pg.io/documentation/1.20/kubectl-plugin/
* https://blog.ovhcloud.com/ovhclouds-internal-databases-infrastructure/
* https://www.alibabacloud.com/blog/postgresql-haproxy-proxy-for-ha-and-load-balance_597618
* https://jjsair0412.tistory.com/7#etc-%EB%B9%84%EB%8F%99%EA%B8%B0-%EB%B3%B5%EC%A0%9C-%EB%B0%A9%EC%8B%9Dvs%EB%8F%99%EA%B8%B0-%EB%B3%B5%EC%A0%9C-%EB%B0%A9%EC%8B%9D
* https://developers.hyundaimotorgroup.com/blog/43
* https://eoriented.github.io/post/replication-2/
* https://lob-dev.tistory.com/entry/High-Availability-%EA%B8%B0%EB%B3%B8%EC%A0%81%EC%9D%B8-%EB%B3%B5%EC%A0%9C-%EA%B0%9C%EB%85%90%EA%B3%BC-%EB%B0%A9%EC%8B%9D
* https://elsboo.tistory.com/51
* https://medium.com/@qodot/postgresql-replication-%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0-dfd481c4fb04
* https://bcho.tistory.com/1391
* https://velog.io/@kubernetes/Cloud-Native-PostgreSQL-1
* https://awslabs.github.io/data-on-eks/docs/blueprints/distributed-databases/cloudnative-postgres
* https://sharing-for-us.tistory.com/15a
