MongoDB는 어떻게 복제되고 샤딩될까?
How MongoDB is replicated and sharded under the hood?

가시다님의 DOIK 2기 스터디를 진행하면서 ZooKeeper를 이용한 MongoDB의 복제와 샤딩 방식에 대해 궁금해져서 정리해보았습니다.
Point 1. MongoDB의 복제 방식

기본적으로 MongoDB는 JSON 기반의 문서 저장소 유형이다. MongoDB의 주 노드는 클라이언트 앱들의 읽기와 쓰기 요청을 모두 받게 되는데, 해당 작업을 수행하고 변화된 모든 내용을 operation logs(oplogs) 에 남기게 된다. 보조 노드들은 운영 로그에 기록된 내용을 같이 연산하여 주 노드와 함께 동일한 데이터를 유지하고자 노력한다. 따라서 운영 로그를 전달하는 방법을 통해 보조 노드가 동일하게 연산을 수행, 데이터의 정합성을 맞추는 방식이라고 이해하면 된다.
그렇다면 주 노드는 언제 교체될까? Primary Node와 Secondary Node 간에 주고 받는 heartbeat 신호를 통해 Primary 노드가 정상적이지 않는 상황이라는 것을 발견했다고 하자. 나머지 Secondary Node들의 투표를 통해 새로운 주 노드를 선발하고, 원래의 주 노드가 다시 돌아오면 원래 주 노드가 Primary Node의 역할을 수행한다.
만약 Primary 하나와 Secondary 두 개가 Replica Sets `rs` 를 구성하고 있다고 했을 때, Primary가 죽고 Secondary 두 개만 남은 상황이 되면, 짝수이기 때문에 단일 노드가 선출될 수 없다. 아래 Replica Sets 구성원이 가진 `members` 라는 JSON 객체를 보면 구성원은 `votes` 라고 하는 투표권을 가지고 있다. 그렇다면 투표권 숫자를 변경해서 Primary가 선출되도록 설정하면 어떻게 되는가?

하지만 MongoDB의 에러 메시지를 보면 `votes fiels value is 2 but must be 0 or 1` 이라는 에러 메시지가 있는데, 만약 Primary에 장애가 생겼고 Secondary 두 명이 투표를 진행하게 되고 각각이 가진 투표권 0이고 1이면 Secondary 두 개가 Election을 진행하면 1표를 받은 Secondary가 Primary로 선출될 수 있지 않을까 생각해본다.

하지만 투표자들의 전체 투표 숫자가 1표라서 전체 투표 숫자(Primary 1개, Secondary 1개, Secondary 0개) 이므로 과반수를 넘지 못하여 1표를 받은 Secondary는 구조상 Primary로 선출될 수 없다. MongoDB는 Election 시에 투표자들의 투표 숫자가 전체 가능한 투표 숫자의 과반수를 넘어야 진행이 될 수 있다는 것을 알 수 있었다. 그렇다고 Primary의 투표권을 0으로 설정한다고 문제를 해결할 수 없는데, 그 이유는 최소한 2개 이상의 투표권이 필요로 하기 때문이다. 투표권을 하나씩 가지고 있는 상태에서 투표를 하는 서버가 3개 이상의 홀수 개로 존재하여야 Primary가 정상적으로 선출된다는 것을 알 수 있다. 짝수 개의 서버일 때는 정상적으로 Primary가 선출되지 못할 것이다.

그래서 Arbiter의 존재가 매우 중요한데, Arbiter는 투표권만을 가지고 있으며 Primary로 선출되지 않는다. Arbiter의 역할은 Primary가 죽고 Secondary가 하나 남았을 때 서버 쪽에서 에러가 발생하게 되는데 이 때 Arbiter를 추가해주면 Secondary가 Primary 역할을 하게 되고 Aribter가 Secondary의 역할을 하게 되면서 서버가 일단 정상적으로 동작하게 된다. 마치 substitution의 조커 역할을 맡는 것이다.
Election이 진행되면 특정한 Secondary는 Arbiter의 투표를 받아 2표를 획득하게 될 것이고 다른 Secondary는 상대방의 Secondary의 투표를 받아 1표를 획득하게 될 것이다. 즉 여기서는 Arbiter가 캐스팅 보트의 역할을 쥐고 있는 것이다. 전체 투표 숫자가 3표인데 과반수 이상을 받아야 Primary로 선출되니 2표를 받았으면 과반수 이상이 맞고 Election이 성공하여 새로운 Primary가 선출된다.

그런데 Election이 진행되었을 때 투표의 우선순위는 정할 수 없을까? 그러니까 승계구조를 만들어서 원하는 Secondary를 콕 찝어 해당 Secondary가 자동으로 Primary를 승계할 수는 없냐는 것이다. 위의 JSON을 보면 `priority` 가 보일 것인데 원하는 멤버를 election 과정에서 primary로 선출될 가능성을 높이는 것이다. 이를 통해 ReplicaSet의 투표 우선순위를 설정할 수 있다. 기본 설정이라면 투표 시간은 아무리 길어도 12초이며, MongoDB 3.6 이상 버전의 드라이버들은 주 노드가 정상 상황이 아닐 경우 실패한 쓰기 연산을 재시도하는 기능이 있다.
한 가지 궁금한 것이 생긴다. 그렇다면 우리는 왜 Arbiter를 필요로 할까? 그냥 새로운 Secondary를 가지고 있으면 그것으로 충분한 것이 아닐까? 하지만 Primary 입장을 생각해보면 Secondary가 3개일 때 그만큼 Primary에 들어가는 부담이 많아지게 된다. Arbiter는 by design 상 Primary로부터 Data Replication을 지원받을 필요가 없다. Primary 선출 시 투표권을 가지고 있을 뿐이다.
Point 2. Sharding이란?
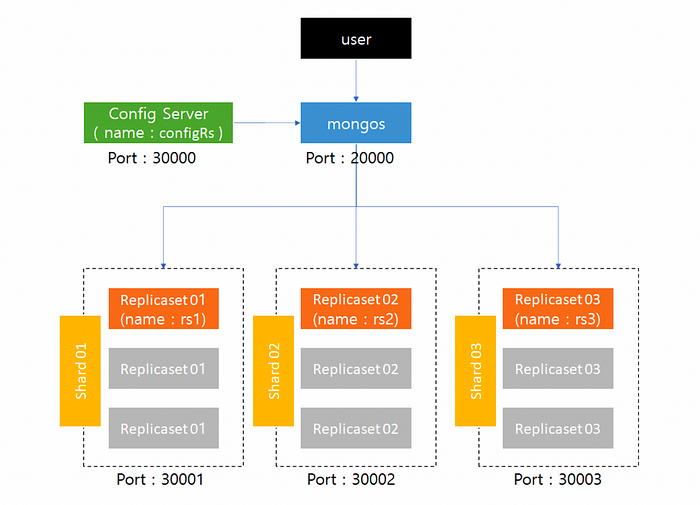
샤딩이란 여러 장비에 걸쳐서 데이터를 분할하는 과정을 의미한다. 각 장비에 데이터의 subset을 넣어 더 많은 수의 비교적 낮은 성능의 장비로 더 많은 데이터를 저장하고 부하를 처리할 수 있다. 컬렉션을 분할한 청크 단위의 데이터를 저장하여 복제 세트로 구성하게 된다. 더 자주 접근하는 데이터를 성능이 좋은 하드웨어에 배치할 수 있고, 지역에 따라 데이터셋을 분할해 주로 접근하는 애플리케이션 서버와 가까운 컬렉션의 도큐먼트에서 서브셋을 찾을 수 있을 것이다. 예를 들어 사용자가 특정한 locale을 기반으로 할 때를 생각해보면 된다.
MongoDB 샤딩을 통해 더 많은 장비(샤드)의 클러스터를 생성하고, 각 샤드에 데이터 서브셋을 넣음으로서 데이터를 쪼갤 수 있다. 샤딩의 목적은 2개, 3개, 10개, 심지어 1천 개의 샤드 클러스터가 하나의 장비처럼 보이게 하는 것이다. 이러한 세부 사항을 Application으로부터 숨기기 위하여 샤드 앞 단에 있는 `mongos` 라는 라우팅 프로세스를 실행한다. 특히 어떤 샤드가 어떠한 데이터를 포함하는 지 알려주는 컨텐츠 목차가 있는데, 이를 `mongos` 라고 부른다. 애플리케이션은 라우터에 연결해 정상적으로 요청을 발행할 수가 있고, 라우터는 어떤 데이터가 어떠한 샤드에 있는 지 알기 때문에 요청을 적절한 샤드로 전달할 수 있게 된다. 요청에 대한 응답이 있으면 라우터는 응답을 수집하고, 필요하다면 응답을 통합하여 원래의 Application으로 되돌리게 된다.
다시 설명하면, `mongos router` 는 청크 샤드 키를 참조해서 `Config Server` 를 만들게 되고, `mongos router` 는 해당 서버에 데이터를 조회하고 반환하는 데 이 때 `Shard Servers` 에 조회를 거치게 된다. 마지막으로 `Query` 에 대한 결과를 조합하고 반환하게 된다. 여기서 `mongos` 의 역할은 다수 구성된 샤드에 대하여 인터페이스 역할을 수행하고, 클라이언트 요청에 대해 올바른 샤드로 라우팅한다. `Config Servers` 는 전체 클러스터의 메타 데이터와 구성 설정을 저장하는 서버이다.
주지할 사실은 직접 샤딩을 애플리케이션 단에서 구현하게 될 경우 Key에 따라서 DB 인스턴스를 선택적으로 고를 수 있는 구조를 가져야할 것이며 특히 다른 샤드 간의 데이터 JOIN 등은 원칙적으로 불가능하기 때문에 구현할 때 잘 설계해야 한다. 특히 샤딩 기능을 사용하게 되면 애플리케이션의 복잡도가 올라간다는 사실을 잊어서는 안되며 하나의 트랜잭션에서는 두 개의 샤딩이 한 번에 접근할 수 없다는 점을 잘 고민하여 설계해야 할 것이다.
Point 3. Zookeeper는 왜 필요한가?
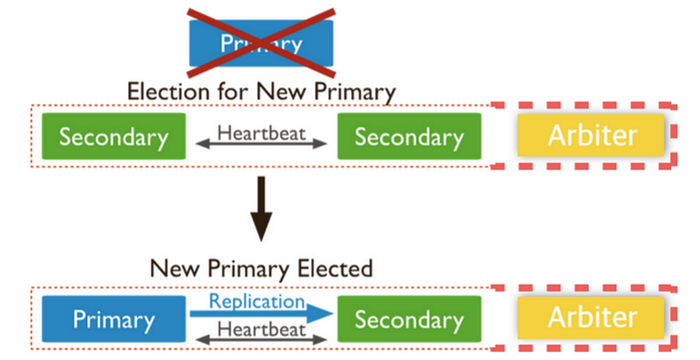
우리가 앞서 살펴본 바와 같이 ReplicaSet이 Primary 1, Secondary 2개, Arbiter 1개로 구성되어 있다면 Primary가 죽었다고 하더라도 Arbiter의 존재로 인해 홀수 개의 투표가 받아들여져 Primary로 선출된다는 사실에 대해 배웠다. 하지만 죽었던 Primary는 어떻게 다시 살려낼 것인가 라는 문제가 있다. 혹은 Arbiter가 죽으면 어떻게 해결할 것인가에 대한 고민도 할 수 있다. 위의 상태에서 아비터가 죽었다고 가정하면, 또 그 상태에서 Primary가 죽으면 어떻게 될까? Election을 통해서 Primary가 선출되지 않을 것이다. 선출할 수 있는 권한을 가진 Arbiter가 없기 때문에 꼭 Arbiter를 먼저 살려내야 할 것이다.
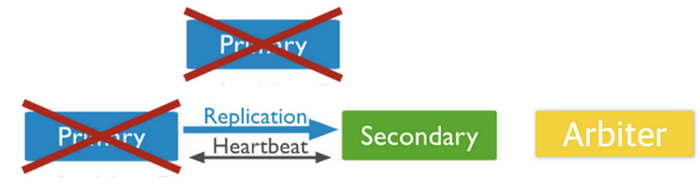
물론 Arbiter는 죽을 일이 거의 없기는 하다. 왜냐하면 투표권을 행사하지만 Replication이 되지 않기 때문에 Client에게 Read를 수행할 일이 사실상 없기 때문이다. 만약 Primary 하나와 Secondary 하나, 그리고 Arbiter 하나가 살아있다고 가정해보자. 이 때 Primary가 죽는다면 남은 Secondary는 Primary로 선출되지 않는다. 이렇게 되면 죽은 ReplicaSets 멤버는 다시 살려낼 필요가 있다.
이제 사용자 입장에서 누가 Primary이고 Secondary인지 알아낼 필요가 있다. 즉, 각 ReplicaSets 서버의 상태를 바라보는 정보 관리 도구가 필요하다. 이 때 관리하는 도구가 바로 ZooKeeper이다. 주키퍼의 사용 용도는 워낙 다양하지만 서버관리 용도로도 사용되고 있다. Zookeeper는 [일반적인 파일 시스템](https://zaccoding.tistory.com/26?category=774827)과 유사하게 각 디렉토리 노드가 있고 이를 `znode` 라고 부르고 있다. 각 노드는 [홀수 개](https://data-engineer-tech.tistory.com/4) 로 이루어져야만 한다.
ZooKeeper를 한 마디로 설명하자면 분산 처리 환경에서도 사용이 가능한 데이터 저장소를 의미한다. 분산 시스템을 coordination 하는 용도이므로 data access가 빨라야 하고 자체적으로도 클러스터링이나 failover 등 장애 대응성이 있어야 한다. 다음의 명령어로 설치해보고 zkserver.sh의 위치를 확인해보도록 하자.
brew install -g zookeeper
cd /usr/local/etc/zookeeper
ls zoo.cfg # config 파일과 zkServer.sh, zkCli.sh의 위치를 파악하는 방법
ls zkServer.sh zkCli.sh
cd /usr/local/Cellar/zookeeper/3.9.1/libexec/bin
zkServer start // zkserver를 시작한다
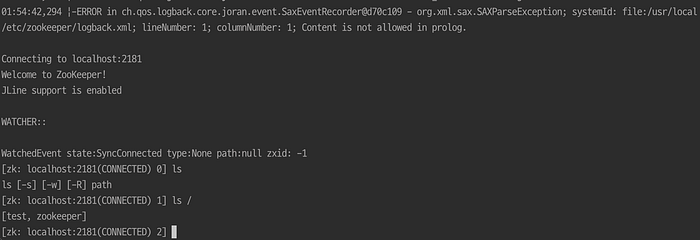
zkCli // zkCLI에 접속할 수 있다
WatchedEvent state:SyncConnected type:None path:null zxid: -1
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /test ''
Created /test
[zk: localhost:2181(CONNECTED) 2] ls /
[test, zookeeper]
[zk: localhost:2181(CONNECTED) 3]`/test` 노드를 생성했는데 주키퍼에 저장되는 노드는 `znode` 라고 부른다. default 값으로 persistent node를 생성한 상태인데, 노드에 데이터를 저장하면 일부러 삭제되지 않는 이상 영구히 저장된다. 이와 달리 Ephemeral Node는 노드를 생성한 클라이언트의 세션이 연결되어 있을 때만 유효하며 클라이언트의 연결이 끊어지는 순간 삭제된다. `quit` 명령어를 통해 끊고 나서 다시 살펴보면 보이지 않는다.
이를 통해 클라이언트가 연결이 되어 있는지 아닌지를 판단할 수 있다. 이러한 기능 덕분에 사용 가능한 모든 채팅 서버를 주키퍼에 등록시켜두고 클라이언트가 접속하면 사전에 정한 기준에 따라 최적의 채팅 서버를 골라줄 수 있다. ( 물론 아래 [동작 플로우](https://jonghoonpark.com/2023/07/13/chatting-system-design)를 보면 서비스 탐색 기능(주키퍼)은 추천 채팅 서버를 반환해 줄 뿐이지 직접 요청을 전달하지는 않는 것을 볼 수 있다. )
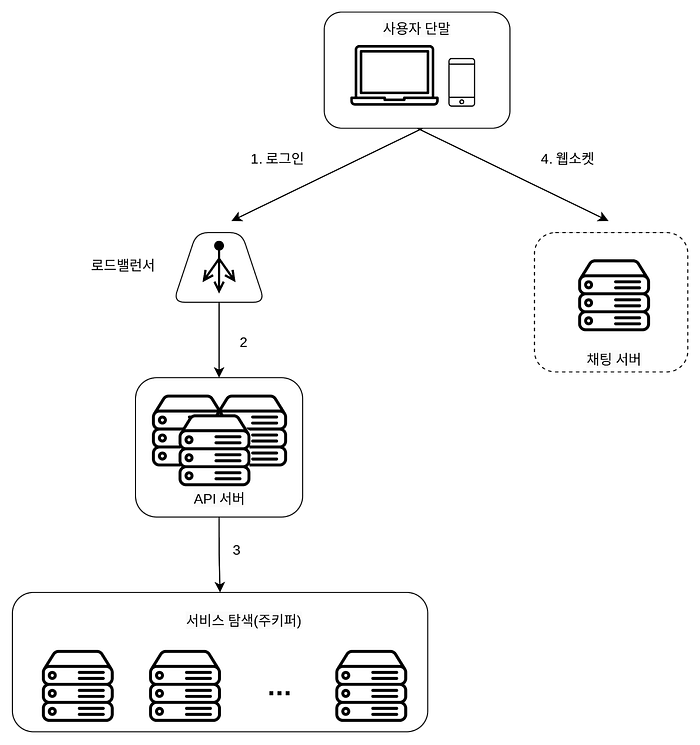

Sequence Node에 대해서도 살펴보자. 노드를 생성할 때 자동으로 시퀀스 번호가 붙는 노드이다. 요즘이야 레디스를 주로 분산 락 구현을 위해 사용하지만 전통적으로는 주키퍼의 시퀀스 노드 번호를 이용하여 분산락을 구현해왔다. Spring Integrations에서 `LockRegistry` 같은 레포를 이용하여 [구현](https://zaccoding.tistory.com/27) 하게 된다. 여러 개의 서버로 구성된 분산 서버가 공유 자원에 접근하려고 했을 때, 하지만 동시에 하나의 작업만 이루어져야 한다고 하면, 그 작업에 락을 걸고 작업을 하는 기능을 구현하는 글로벌 락에도 사용된다.
특히 ZooKeeper에서 가장 주목할 만한 기능은 바로 `watch` 기능이다. 이를 통해 큐를 구현할 수 있기 때문이다. ZooKeeper 클라이언트가 특정 `znode` 에 `watch` 를 설정하면 새용이 가능한데, 만약 `/app1/p_2` 라고 하는 `znode` 에 `watch` 를 설정하여 Watcher를 생성했다고 가정해보자. 그렇다면 `/app1/p_2` 라고 하는 `znode` 가 변경되면 watch를 설정한 Client에 이벤트 변경을 고지한다. 그리고 이벤트 변경이 고지되면 해당 Watcher는 삭제된다. 특정 `znode` 에 `watch` 를 설정하고 다음과 같은 이벤트를 감지하도록 하면, 이를 알려주고 삭제되는 one-time trigger로 동작하는 것이다.
- NODE_CREATED : 노드가 생성되었음을 감지한다
- NODE_DELETED : 노드가 삭제되었음을 감지한다
- NODE_DATA_CHANGED : 노드의 데이터가 변경되었음을 감지한다
- NODE_CHILDREN_CHANGED : 자식 노드가 변경되었음을 감지한다
큐에서 어떻게 사용될까? Queue에서 Child Node를 Sequence Node로 구성하면 새롭게 생성되는 메시지들은 해당 Sequence Node로 순차적 생성된다. 해당 큐를 읽는 클라이언트가 이 Queue의 Node를 watch 하도록 설정하면 해당 클라이언트는 새로운 메시지가 들어올 때마다 callback을 받아서 Message Queue의 Pub/Sub처럼 구동하도록 설정할 수 있다. 대용량 메시지의 성격은 Kafka를 잘 활용하고, ZooKeeper는 클러스터 간 통신용 큐를 활용한다고 볼 수 있을 것이다. 우리가 MongoDB의 클러스터링에 대해서 이야기를 하고 있었으므로, 다시 돌아오면, ZooKeeper 서비스에 Ephermal Node를 설정해주고 동시에 `mongod` 명령어를 통해 `mongo rs server` 를 생성할 수 있을 것이다. 각 MongoDB replica set 멤버에 해당되는 Ephermal Node가 생성되었다고 하자. 해당 `znode` 가 생성된 것을 Watcher가 감지하고 zookeeper에 Replica Sets의 상태를 `rs mongo server` 에서 받아와서 감지한다.
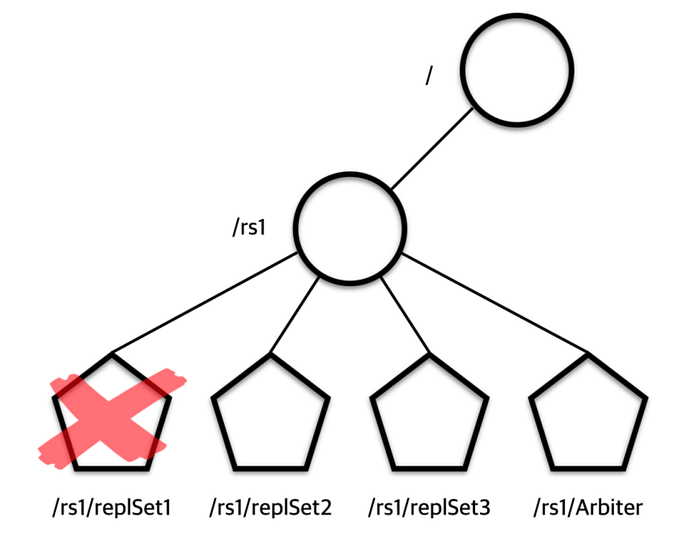
만약 에러가 생겨 특정 MongoDB Server가 죽었을 때는 ZooKeeper Server와 커넥션이 끊겨 해당 Ephermal Node가 삭제되게 된다. 이를 watcher가 감지해 변경된 replicasets의 상태를 ZooKeeper에 갱신해준다. 즉, DELETED event를 감지하고 rs의 상태를 갱신하는 것이다. 이러한 과정을 통해 죽었던 mongo server를 되살릴 수 있게 된다.
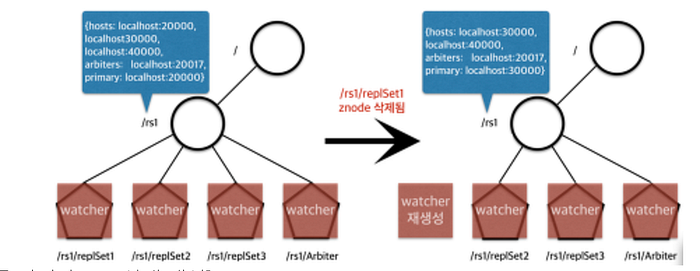
따라서 ZooKeeper에 대해서 기본적으로 이해하게 되면 샤딩의 동작 원리에 대해서도 이해할 수 있게 된다.







