ServletContainer와 SpringContainer는 무엇이 다른가?
Controller 1개는 어떻게 수십 만개의 요청을 처리하는가
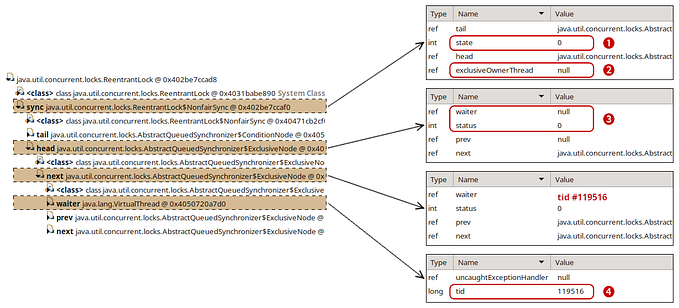
21/10/10: Java Reflection을 통해 ServletContainer가 SpringContainer의 Bean을 추적하도록 하는 절차에 대해 업데이트 했습니다.

살면서 첫 기술면접을 처음으로 볼 수 있는 기회가 생겼다. 지난 10월 초, 모 사의 서류 전형에 합격하고 기술면접을 보러 구직 청원휴가를 받고 사회로 나갔다. 면접 일정이 6일 전에 나왔는데, 연휴가 껴있는 마당이라 급하게 결재를 받고 보고를 드린 뒤 휴가를 나왔다. 1년 2개월 전이 최신 자료인 포트폴리오와 GitHub 레포지토리를 바탕으로 처음부터 다시 공부해갔다.
도대체 과거의 나는 어떻게 코드를 짰고 무슨 생각을 했는지 도저히 기억나지 않았기 때문이다. 기초 문법부터 Spring 프레임워크 기본, Data JDBC와 JPA라는 ORM 프레임워크까지 아예 기억이 나질 않아서 4일 정도 새벽을 꼬박 벼락치기를 하며 공부했다.
자세한 면접 후기를 공유하기는 어렵겠지만, 내 스스로에 닥친 질문 중 대답을 제대로 못한 것이 두 가지 있었다. 하나는 ApplicationContext와 ServletContext의 life-cycle의 차이를 제대로 알고 있어야 답변할 수 있는 질문이었고, 또 하나는 @Transactional 어노테이션에 대한 작동방식을 깊이 있게 이해하고 있느냐에 대한 질문이었다.
이 두 가지 질문은 Spring 프레임워크를 공부해 본 학생 개발자라면 누구나 단편적인 지식을 이야기할 수 있다. 첫 번째 질문의 경우에는 하나의 요청이 들어올 때 Thread 하나씩 해당 요청을 담당하는데, 매번 Tomcat에 접근하여 HttpSession으로부터 세션을 get하는 비용이 상당하므로 이를 ThreadLocal 변수에 만들어서 이용자의 세션정보(JWT Token 정보)를 저장해서 필요할 때 바로 꺼내쓰도록 설계했던 나의 프로젝트 경험을 이야기하자, 면접관 분이 follow-up을 하시는 맥락에서 나왔다.
이 때 면접관이 질문했다. 그렇다면 Spring Bean은 어떻게 관리되는가? 여러 개의 톰캣 인스턴스가 쓰레드 별로 생성되고 관리되는데, 톰캣 인스턴스와 Spring Bean의 연관관계는 어떻게 되는가? 나는 순간 다음과 같은 생각이 들었다: Spring Bean은 Singleton 패턴으로 이루어지므로 한번 Bean이 IoC Container에 따라 생성되면 요청이 1개이건 10만 개 이건 홀로 다 처리해야 한다는 소리인데, 이게 맞는가? 순간적으로 의문이 들었다. 내가 알고 있는 지식이 잘못된 것인가? BeanFactory는 ApplicationContext가 extends하는 것인데, 빈을 생성하고 의존관계를 설정하는 기능을 담당한다. 그렇다면 내가 알고 있는 싱글톤 패턴이라는 것이 BeanFactory에서 각자 꺼내서 쓰는 것인가? 어, 그런데 이건 Bean의 스코프가 prototype으로 변경되었을 때 이야기 아닌가?
결국 지식의 부족이었다. 위에서 언급한 물음표가 머릿속을 휘젓고 지나가자, 내가 무슨 말을 하는 지도 모르는 답변을 해버렸다. Prototype 스코프가 default다, Bean을 만들어주는 BeanFactory 자체가 Singleton이라는 뜻이다 라는 잘못된 내용으로 답변했다. 벼락치기의 한계란 이런 것일까? Spring Bean이 Singleton Pattern이고, thread-safe하지 않으므로 stateless하게 설계해야 한다는 것은 창세기 1장 1절에 나올 것만 같이 모두가 알고 있는 지식이다. 그런데 조금만 서로 연관이 있는 지식을 묶어서 물어보니 나의 앎이 흔들리는 것이다. 이게 맞는 것인가 — 라는 의문. 면접장에서 물음표가 씨게 던져지자 내 자신이 흔들리는 모습을 발견할 수 있었다.
오늘은 내가 정확히 답하지 못했던 첫 번째 질문에 대해 이야기해보고자 한다. 바로 Controller 1개는 어떻게 수십 만개의 요청을 처리하느냐에 대한 물음에 답하고자 한다. 이를 넘어, Servlet과 Spring의 Container가 서로 어떻게 다르며, 또 동작 방식이 어떻게 상이한 지에 대해 최대한 탐구하고자 한다.
Controller 1개는 어떻게 수십 만개의 요청을 처리하는가
일단 WAS에 대한 학습요소로 많이 쓰이는 것이 Tomcat이다. Tomcat은 default로 설정되어 있는 worker thread가 200개인 것으로 알고 있다. Tomcat은 하나의 프로세스에서 동작하고, thread pool을 만들어 HttpRequest가 들어왔을 때 하나씩 쓰레드를 재사용 및 재배정을 진행한다. 쓰레드 풀에 생성될 수 있는 쓰레드 개수의 max를 우리가 지정할 수 있는데, 실질적으로는 idle한 상태로 남겨지는 쓰레드의 최소 개수도 있다. 요청이 많아지면, 그에 따라 실질적으로 큐에 쌓였다가 쓰레드가 만들어지는 등 일반적인 쓰레드 풀의 동작을 한다. 아니, Request 별로 Thread가 별도로 생성되고 이에 따라 각각의 ServletContext를 갖는 것은 분명한데, 이 쓰레드들이 하나의 Controller 객체를 공유한다는 것이 가능한가? 라는 질문을 갖게 되었다.
그런데 조금만 찾아보니 나와 비슷한 질문을 가진 사람들이 여럿 있다는 사실을 발견할 수 있었다. Controller 객체 하나를 생성하면 객체 자체는 Heap에 생성되지만, 해당 Class의 정보는 Method Area(또는 Permanent Area)에 저장된다는 것이다. 결국 힙 영역이던 메소드 영역이던 모든 쓰레드가 객체의 Binary Code 정보를 공유할 수 있다는 뜻이다. 공유되는 정보를 사용하기 위하여 굳이 Controller 객체를 사용하고 있는 쓰레드나 Controller 객체 자체가 Block될 필요는 없다는 것이다.

공유는 공유다. 내부적으로 상태를 갖는 것이 없으니, 내부의 상태를 변경할 일이 없고 그저 메소드에 대한 정보만 ‘같이 공유해서’ 쓰면 되는 것이기 때문에 동기화에 대한 걱정을 할 필요가 없다.
배우 공유를 보고 잘 생겼다. 이목구비가 뚜렷하다. 하면 다른 사람도 보고 와 잘 생겼다. 하고 느끼면 되는 거지, 내가 이 배우 공유를 어떻게 또 성형을 시키겠다. 라는 식으로 상태를 부여해서 변경하는 것은 아니지 않는가?
Controller가 내부적으로 상태를 갖는 것이 없으니, 그냥 메소드 호출만 하면 되기 때문에 굳이 동기화할 이유도 없고 명분도 없고 그저 처리 로직만 ‘공유되어’ 사용되는 것이기 때문에 몇 십만개의 요청이 들어오든 상관없다는 것이다.
비슷한 사례를 하나 더 들자면, Tomcat의 MaxThreadPoolSize의 default value는 200개인데, DBCP인 HikariCP는 maximumPoolSize의 default value는 10개이다. Connection 객체를 10개만 공유하더라도 상태에 대한 변화가 없기 때문에 Thread 200개가 동시에 사용할 수 있다.
만약 상태를 가지는 Bean을 만들어야 한다면, scope=prototype으로 지정해야 할 것이다. 그런데 내가 scope를 prototype으로 지정하는 경우는 거의 보지 못했다. 내가 코딩을 시작한 지 얼마 안되어서 그런건가? 일단 stateful beans라면 scope를 prototype으로 만들어야 할텐데, bean에 cache가 남지 않기를 바라면 prototype으로 지정할 수 있겠다. 이렇게 만드는 경우가 있는가? 아무리 생각해도 떠오르지 않는다. 설상 stateful해야 한다고 치더라도, 최대한 DI를 활용하여 외부에서 하위 객체를 주입한다면 굳이 singleton을 쓰지 않을 이유가 무엇이 있을까 싶다. 오히려 DI를 활용하는 것이 훨씬 유지보수에 좋지 않나.
하여간 앞으로는 Spring Bean을 만들 때는 stateless하게 만들어야 한다는 교훈을 얻었다. 지식적으로는 알고 있었지만, 그 이유를 알 수 있는 계기가 되었다. 스프링 Bean이 상태를 갖게 되었을 때는 그 상태를 공유하는 모든 쓰레드들로 부터 안전할 수 있게 동기화를 해줘야 하고 동기화를 하는 순간 싱글톤으로써의 혜택이 날아간다고 봐야하기 때문이다.
서블릿 컨테이너와 스프링 컨테이너는 어떻게 다른가?
Servlet에 대하여
Servlet은 Java EE의 표준 중 하나로 javax.servlet Package를 기반으로 Server에서 동작하는 Class들을 의미한다. 각 Servlet은 init(), service(), destory() 3개의 method를 반드시 정의해야 한다.
- init() : init()은 Servlet 생성시 호출된다. Parameter로 javax.servlet.ServletConfig Interface 기반의 Instance가 넘어오는데, Servlet을 초기화 하고 Servlet이 이용하는 자원을 할당하는 동작을 수행한다.
- service() : Servlet으로 요청이 전달 될때마다 호출된다. 실제 Service Logic을 수행한다.
- destroy() : Servlet이 삭제될때 호출된다. Servlet에서 이용하는 자원을 해지하는 동작을 수행한다.
웹 서버의 측면에서 서블릿을 바라보면, 1) Socket의 생성 2) Input/OutputStream의 생성 등의 업무를 개발자를 대신해서 진행해준다. Container는 Servlet의 생성주기(life-cycle)을 관리하고, 매번 요청이 들어올 때마다 새로운 쓰레드를 요청 별로 부여한다. 즉, The Container runs multiple threads to process multiple requests to a single servlet (in one process). 인 것이다.
public class MyServlet extends HttpServlet {
private Object thisIsNOTThreadSafe; protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
Object thisIsThreadSafe;
}
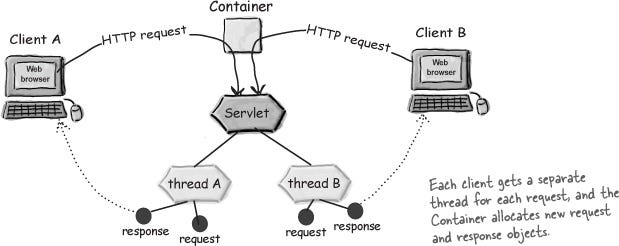
Q: 하나의 클라이언트에 하나의 쓰레드가 부여되는 것 아닌가요? 각각의 클라이언트는 자신만의 쓰레드에서 동작하는데요?
A: 요청 당 하나의 쓰레드다. Container는 누가 요청을 보냈는지에 대해서는 관심이 없다. 새로운 요청은 새로운 쓰레드를 만들어낸다.
Q: Thread-per-request를 Thread-per-connection에 우선해서 쓰는 이유는 뭐죠?
A: Scalability에 유리하다. Java 쓰레드는 비용이 비싼데, 1Mb 메모리 segment가 하나씩 붙는다. active 상태이건 idle 상태이건 상관이 없다. 커넥션 하나당 하나의 쓰레드에 붙이면, 쓰레드는 요청이 계속 오기까지 idle 상태로 대기를 타야할 것이다. 궁극적으로 framework가 새로운 커넥션을 만들지 못하게 될 것이고 (쓰레드를 더 만들 수가 없어서)… 아니면 기존 커넥션을 끊어버리든가 해야겠죠.. 즉, 커넥션이 연결되는 동안 스레드가 유지되어야 합니다. 그런데 thread-per-request를 쓰면 request가 진행될 때만 쓰레드가 개입을 하니까, 서비스는 수만명이 사용한다고 하더라도 현재 사용중인 요청에만 쓰레드를 투입시키면 되니까 경제적이다 이겁니다.
다만, 클라이언트가 지속적으로 요청을 날려야 하는 상황에서는 HTTP Keep-alives를 사용하여 Connection 별로 Thread를 지속적으로 유지하도록 할 수 있습니다.
ServletContainer에 대하여

Servlet Container(Web Container)는 Servlet Instance를 생성하고 관리하는 역할을 수행한다. HTTP 요청을 도식화하면 다음과 같다.
- Web Browser에서 Web Server에 HTTP Request를 보내면, Web Server는 받은 HTTP 요청을 WAS Server의 Web Server에 전달한다.
- WAS Server의 Web Server는 HTTP 요청을 Servlet Container에 전달한다.
- Servlet Container는 HTTP 요청 처리에 필요한 서블릿 인스턴스가 힙 메모리 영역에 있는 지 확인한다. 존재하지 않는다면, Servlet Instance를 생성하고 해당 Servlet Instance의 init() method를 호출하여 Servlet Instance를 초기화한다.
- Servlet Container는 Servlet Instance의 service() 메소드를 호출하여 HTTP 요청을 처리하고, WAS Server의 Web Server에게 처리 결과를 전달한다.
- WAS Server의 Web Server는 HTTP 응답을 Web Server에게 전달하고, Web Server는 받은 HTTP 응답을 Web Browser에 전달한다.
우리가 대표적으로 알고 있는 ServletContainer는 Tomcat이다. ServletContainer는 하나의 WebApplication 하나씩 붙는다. ServletContainer인 Tomcat도 자바 프로그램이기 때문에, 하나의 JVM이 붙는다. 즉, one WAS per one JVM인 것이다.
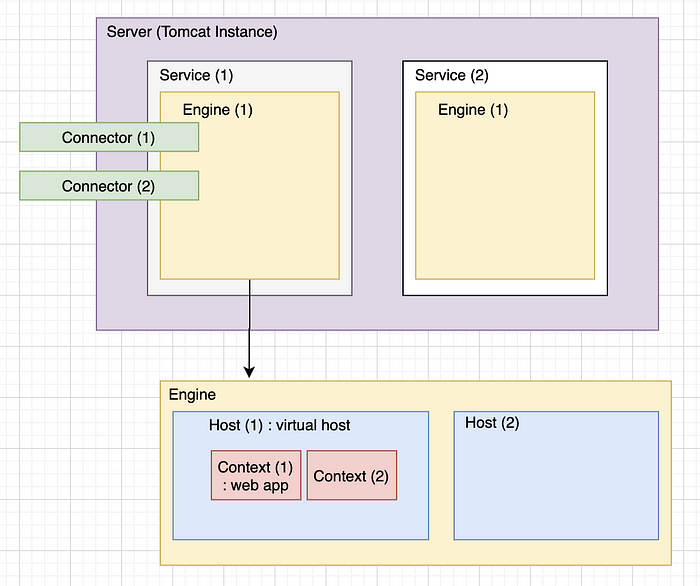
Application이 시작되면 Servlet Listener는 사전에 지정된 역할을 수행하며, Servlet을 생성하거나 제거하는 역할을 수행한다. 서블릿 API는 Servlet과 ServletConfig 인터페이스를 구현해 제공되는데, GenericServlet 추상클래스가 위 두 인터페이스의 추상 메서드를 구현하고 HttpServlet이 GenericServlet을 상속받는다. 여기서 doPost와 doGet의 메소드가 나온다.
Q: Apache와 Tomcat의 차이는 무엇인가요?
A: Client에서는 미리 정해진 HTTP 규격에 따라 요청을 보내게 된다. HTTP를 해석한 후, 그에 맞는 데이터 형식으로 보내주는 것이 Web Server가 할 일이다. 요청을 데이터와 단순 매칭을 하고, 이를 HTTP에 맞게 돌려주면 되므로 이러한 과정을 Static Web Server라고 부른다.
하지만 이러한 형태의 사이트에서는 동적인 기능을 제공할 수 없게 된다. 이러한 문제를 해결하기 위해서 Web Application Server를 사용하게 된다. WAS는 일부 Web Server의 기능과 Web Container로 함께 구성되는데, 앞단의 일부 Web Sever는 HTTP 요청을 받아 Web Container로 넘겨준다.
Web Container는 내부 프로그램 로직 처리를 한 후, 데이터를 만들어서 Web Server로 다시 전달한다. Web Server에 따른 처리를 Java 진영에서는 Servlet Container라고 부르고 있다. Servlet Container의 예시로는 Tomcat이 있는데, Tomcat Server가 요청을 받으면 Tomcat Engine이 요청에 맞는 Context를 찾고, 해당 Context는 본인의 web.xml을 바탕으로 전달받은 요청을 Servlet에 전달하여 처리되도록 한다.
Tomcat도 자바 프로그램인 만큼, 사용자의 컴퓨터에 설치된 자바 구동환경과 JVM 위에서 실행된다. 자바 프로그램 하나에 JVM 하나가 구동된다. 참고로, Spring Boot에는 Embedded Tomcat이 있어, 데이터를 처리하고 DB에 스스로 영향을 줄 수 있다.
Apache Web Server는 멀티 프로세스와 멀티 쓰레드 방식을 함께 사용할 수 있다. 항상 idle한 수의 프로세스 및 쓰레드를 생성해두므로, 요청이 들어왔을 때 새로운 프로세스나 쓰레드가 생성되는 것을 기다릴 필요가 없다. 평소에는 요청 하나가 쓰레드 하나에 대응을 하다가, 사용자의 접속이 증가하면 Apache MPM 방식에 따라 프로세스를 fork하거나 쓰레드를 할당한다.
이와 달리 Tomcat은 멀티 쓰레드 방식을 사용한다. 쓰레드 풀을 관리하고 있는 Acceptor Thread 하나가 존재하고, 이를 관리하는 여러 개의 Thread를 동시에 띄워둔다. 클라이언트로부터 요청이 들어오면, Acceptor Thread가 available worker thread와 connection을 맺어준다. worker thread는 응답을 받아 Tomcat engine에 request를 보내 request를 처리하고, request header와 associated virtual host and contexts에 따른 적합한 응답을 보내달라고 한다. 이후 Tomcat은 client와의 socket 통신이 열리면 다시 worker thread를 활성화 한다.
Q: Apache는 멀티 프로세스이고, Tomcat은 멀티 스레드입니다. 그렇다면 Apache 웹 서버 하나에 여러 개의 Tomcat Instances를 띄우면 어떨까요?
A: 여러 개의 Tomcat Instances를 띄우겠다는 것은, JVM 여러 개를 동시에 돌리겠다는 의미다. Tomcat Engine과 Instance는 원래 분리가 가능한 구조로 설계되어 있다. 그렇다면 JVM이 일정한 minimum size가 있다는 것을 생각해볼 때, memory usage 입장에서 가상 메모리 스와핑 오버헤드가 발생할 수 있다는 점 때문에 메모리 누수가 상당할 것으로 보인다. 하지만 JVM 하나 프로그램이 동작하지 않을 때, 다른 Tomcat Instance에는 영향을 받지 않는다는 장점이 될 수 있겠다. 또한, JVM 요구사항이 다른 경우에는 무조건 여러 개의 인스턴스를 띄우는게 유일한 방법이 될 것 같다.MSA 기반에 따라 서비스별로 나눠진 WAR 파일을 배포해야 한다고 가정해보자. 그렇다면 하나의 톰캣 엔진으로 여러 인스턴스를 띄워서 WAR 파일 개수만큼 인스턴스를 구동시킬 수 있을 것이다. 단, 이럴 경우 여러 개의 인스턴스가 모두 동일한 하나의 톰캣 위에서 운영되니 해당 톰캣에 문제가 발생할경우 모든 인스턴스에 문제가 전파가 될 것이다.
Q: JVM이 Servlet을 실행하는 것과, 일반 자바 클래스를 실행하는 것에 차이가 있나요?
A: JVM에서의 호출 방식은 서블릿과 일반 클래스 모두 같으나, 서블릿은 main() 함수로 직접 호출되지 않는다는 차이가 있다. 서블릿은 Tomcat 같은 Web Container에 의해 실행되는 것이다. Container가 web.xml을 읽고 서블릿 클래스를 class loader에 등록하는 절차를 밟는다.
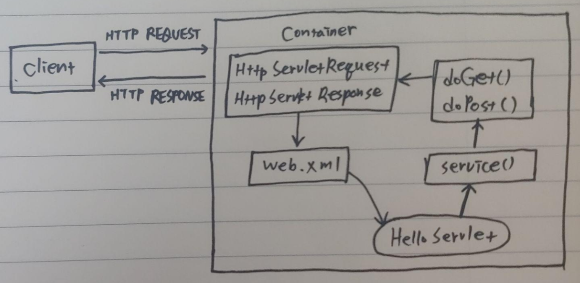

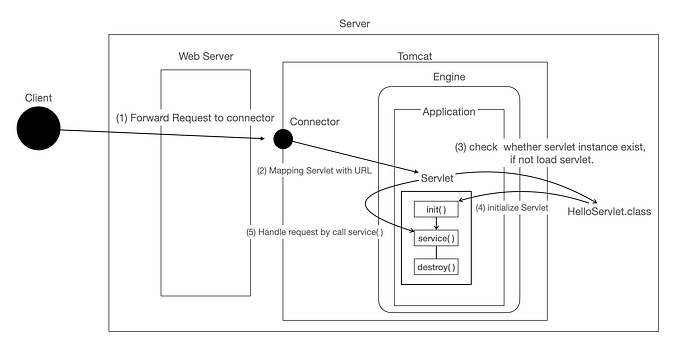
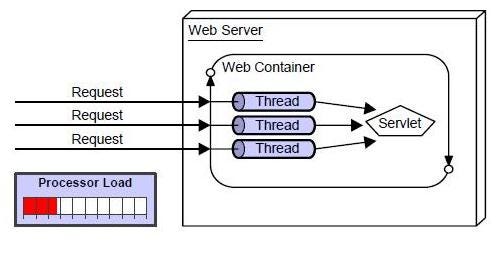
HttpRequest가 Servlet Container로 새로이 들어오면 Servlet Container는 HttpServletRequest, HttpServletResponse 두 객체를 생성한다. GET/POST 여부에 따라 doGet() 이나 doPost()를 실행하게 되며, 동적 페이지 생성 후, HttpServletResponse 객체에 응답을 보낸다. 이 때, 각각의 Servlet 클래스는 JVM의 Class Loader에 의해 로딩된다. Java Servlet container는 서블릿 생성자를 호출하고, 각각의 서블릿 생성자는 어떠한 매개변수도 받지 않는다.
HTTP 요청 처리 과정을 보면 Servlet Instance는 HTTP 요청이 올 때마다 기존의 Servlet Instance를 이용한다. 즉, 하나의 Servlet Instance가 여러개의 HTTP 요청을 동시에 처리하게 된다. 따라서 Servlet Instance는 Thread-Safe하지 않다. Thread-Safe한 변수를 이용하기 위해서는 Method의 지역변수를 이용해야 한다. Servlet Container는 사용되지 않아 제거되야할 Servlet Instance의 destory() method를 호출하고 JVM의 GC(Garbage Collector)에서 Servlet Instance를 해지할 수 있도록 표시해둔다. GC는 표시된 Servlet Instance를 해지한다.
Spring Container는 어떻게 생성되는가?


Spring Container는 Bean 생명주기를 관리한다. Bean을 관리하기 위해 IoC가 이용된다. Spring Container에는 BeanFactory가 있고, ApplicationContext는 이를 상속한다. 이 두 개의 컨테이너로 의존성 주입된 빈들을 제어할 수 있다.
- WebApplication이 실행되면, WAS(Tomcat, ServletContainer per process)에 의해 web.xml이 로딩된다.
- web.xml에 등록되어 있는 ContextLoaderListener가 Java Class 파일로 생성된다. ContextLoaderListener는 ServletContextListener 인터페이스를 구현한 것으로서, root-content.xml 또는 ApplicationContext.xml에 따라 ApplicationContext를 생성한다. ApplicationContext에는 Spring Bean이 등록되고 공유되는 곳인데, Servlet Context는 Spring Bean에 접근하려면 Application Context를 참조해야 한다. ApplicationContext도 ServletContainer에 단 한 번만 초기화되는 Servlet이다. 코드 참고하기
- ApplicationContext.xml에 등록되어 있는 설정에 따라 Spring Container가 구동되며, 이 때 개발자가 작성한 비즈니스 로직과 DAO, VO 등의 객체가 생성된다.
- Client로부터 Web Application 요청이 왔다. Spring의 DispatcherServlet도 Servlet이니 이 때 딱 한 번만 생성된다. DispatcherServlet은 Front Controller 패턴을 구현한 것이다. 처음에 Request가 들어오면, Dispatcher Servlet으로 간다. web.xml에는 서블릿이 등록되어 있는데, Dispatcher Servlet도 Servlet이기 때문에 web.xml에 등록이 되어 있다. 모든 요청이 오면 Dispatcher Servlet로 가라고 하고 등록을 시켜 놓는다.
- 그러면 그에 맞는 요청에 따라 적절한 Controller를 찾는다. 핸들러는 컨트롤러보다 더 큰 개념인데, 핸들러 매핑을 통해서 요청에 맞는 컨트롤러를 찾아준다. HandlerMapping에는 BeanNameHandlerMapping 이 있어, Bean 이름과 Url을 Mapping하는 방식이 default로 지정되어 있다.
- HandlerMapping에서 찾은 Handler(Controller)의 메서드를 호출하고, 이를 ModelAndView 형태로 바꿔준다.
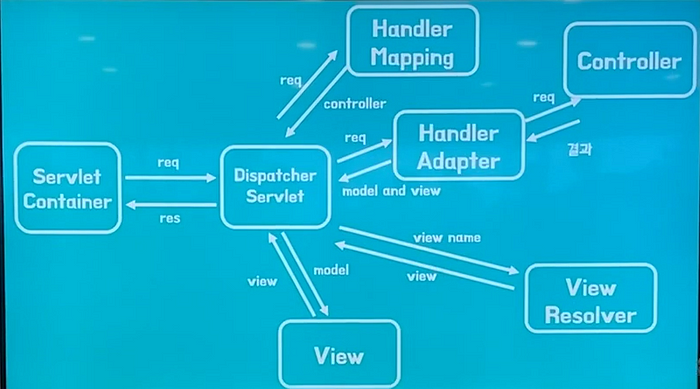
결국 개발자가 작성한 비즈니스 로직도 ServletContainer가 관리하게 되고, Spring MVC도 ServletContainer가 관리하고 있는 Servlet 한 개를 의미한다. Spring MVC로 들어가는 모든 요청과 응답은 DispatcherServlet이 관리하고 있는 것이다. 물론 Spring Container는 Spring의 자체 Configuration에 의해 생성되기는 하다. (Spring Boot uses Spring configuration to bootstrap itself and the embedded Servlet container.)
아무튼 요는 Servlet Container는 Process 하나에 배정되어 있는 것이요, 이에 따르는 요청들은 Thread 별로 처리하도록 ThreadPool에서 역할을 배정시키는 것이다. 그 중, 클라이언트가 임의의 서블릿을 실행하라고 요청했는데 만약 최초의 요청이면 init()을 실행하고, 아니라면 새로 서블릿을 만들지 않고 메소드 영역에 있는 서블릿을 참고해서 service()를 실행하는 것이다. 이렇게 개발자가 아닌 프로그램에 의해 객체들이 관리되는 것을 IoC(Inversion of Control)이라고 한다.
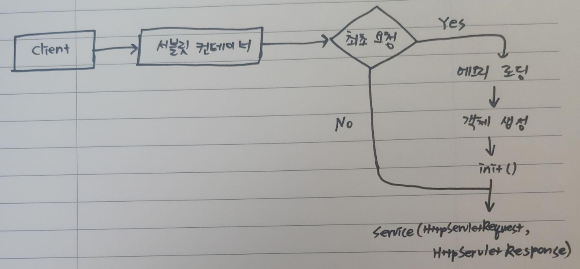
Spring Web MVC가 없던 과거에는, URL마다 Servlet를 생성하고 Web.xml로 Servlet로 관리했다. URL마다 서블릿이 하나씩 필요하다 보니, 매번 서블릿 인스턴스를 만들어야 했다. 그런데 Dispatcher Servlet이 도입된 이후에는 FrontController 패턴을 활용할 수 있게 되면서 매번 서블릿 인스턴스를 만들 필요가 없어졌다. 또한, View를 강제로 분리하는 효과도 볼 수 있게 되었다.
Spring Boot는 어떻게 동작하는가?
Spring Boot는 Embedded Tomcat을 갖고 있다. 원래는 web.xml에 URL별로 일일이 Bean을 매칭시켜야 하지만, 그러는 것은 불가능하니 MVC 패턴을 활용하여 모델(비즈니스로직), 뷰(화면), Controller(최초 Request를 받는 곳)으로 나누고 개발을 하는 것이다. 실행흐름은 다음과 같다.
- DispatcherServlet이 스프링에 @Bean으로 등록되어진다.
- DispatcherServlet 컨텍스트에 서블릿을 등록한다.
- 서블릿 컨테이너 필터에 등록설정 해놓은 필터들을 등록한다.
- DispatcherServlet에 각종 핸들러 매핑(자원 url)들이 등록된다. (컨트롤러 빈들이 다 생성되어 싱글톤으로 관리되어 진다.)
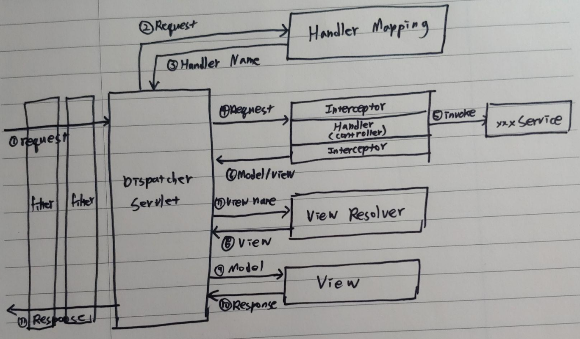
여기서 DispatcherServlet은 FrameworkServlet을 상속하고, 이는 또 다시 HttpServlet을 상속한다. 여기서 주의할 점은, ServletContainer처럼 요청이 왔을 때 객체를 생성하는 것이 아니라 이미 @Controller가 @Bean Singleton으로 등록되어 있다는 것을 상기할 필요가 있다.
- FrameworkServlet.service()가 호출되면
- FrameworkServlet.service()는 dispatch.doService()를 호출하고
- dispatch.doService()는 dispatch.doDispatch()를 실행하고
- doDispatch()는 AbstractHandlerMapping에서 Handler(Controller)를 가져온다.
- Interceptor를 지나서 해당 Controller Method로 이동한다.
- 해당 Handler는 ModelAndView를 리턴한다. @RestController 라면 컨버터를 이용하여 바로 결과값을 리턴할 것이다. View에 대한 정보가 있으면 ViewResolver에 들려 View 객체를 얻고, View를 통해 렌더링을 한다.
rootApplicationContext vs childApplicationContext

Spring Web MVC에는 총 3가지의 Context가 존재한다. 하나는 ServletContext이다. Servlet API에서 제공하는 context로 모든 servlet이 공유하는 context이다. 특히, Spring Web MVC에서는 ServletContext가 WebApplicationContext를 가지고 있다. 또 하나는 ApplicationContext로, Spring에서 만든 애플리케이션에 대한 context를 가지고 있다.
마지막으로, WebApplicationContext란 Spring의 ApplicationContext를 확장한 인터페이스로, 웹 애플리케이션에서 필요한 몇 가지 기능을 추가한 인터페이스다. 예를 들면 WebApplicationContext의 구현체는 getServletContext라는 메소드를 통해 ServletContext를 얻을 수 있다. Spring의 DispatcherServlet은 web.xml을 통하여 WebApplicationContext를 바탕으로 자기자신을 설정한다.

Context는 계층 구조를 가질 수 있는데, 예를 들어 부모-자식 관계이거나 상속 관계일 수 있다. 하나의 root WebApplicationContext(또는 root-context.xml)밑에 여러 개의 child WebApplicationContext(또는 servlet-context.xml)를 가질 수 있다. Data Repository나 비즈니스 서비스와 같이 공통 자원은 root에 두고, DispatcherServlet 마다 자신만의 child Context를 갖도록 만들어 자신들의 Servlet에서만 사용할 빈들을 가지고 있도록 한다.
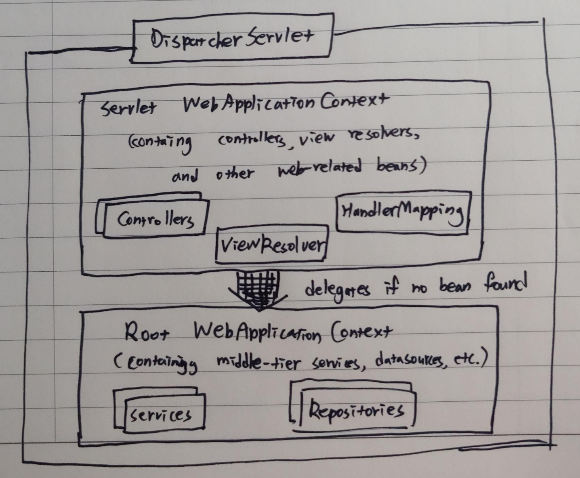
Servlet은 어떻게 Spring Container를 look-up하나?
그렇다면 다음과 같은 질문이 생긴다. 서블릿은 어떻게 스프링 컨테이너를 룩업할 지를 결정하나? 어떠한 방식으로 스프링 컨테이너와 소통하는 걸까?
Spring의 Bean은 Servlet이라기 보다는, Container가 Reflection을 통해 만들어낸 POJO라고 볼 수 있다. 서블릿은 이러한 POJO를 바탕으로, Spring Container에서 look-up해서 서블릿 컨테이너에 올려 마치 서블릿처럼 사용하도록 한다. 예를 들어, 스프링의 Object들이 HttpRequest를 listening 할 수 있도록 내부적으로 프록시 역할을 해주는 것이다.
고언을 주신 Bona Lee님께 감사드린다.
스프링 컨테이너는 Bean Initializing 작업을 거친다. Spring Container에서 Bean은 Bean Definition 객체로 정의해둔 후, 객체를 생성한다. Bean 생성 시 Bean Definition 정의에 따라 객체 생성에 대한 정보를 참조한다. 이후, Java Reflection을 통해 객체를 생성한다.
Container가 Bean 생성 시, Service-Locator 패턴으로 의존성을 주입하며 생성한다. Service-Locator 패턴은, cache라는 map 객체에서 home 객체를 찾은 결과를 보관하여 저장한다. 먼저 cache에서 해당 객체를 찾아보고, 존재하지 않으면 메모리에서 해당 객체를 찾는 방식이다. 메모리에서 찾으면 0.01ms도 소요되지 않으므로, 큰 성능 향상을 가져올 수 있겠다. 객체를 사용하는 곳에서 생성해서, 객체 간에 강한 결합도를 갖는 것이 아니다. 외부 컨테이너에서 생성된 객체를 주입함으로서 객체 결합도를 낮추는 효과가 있다.
public class ServiceLocator {
private InitialContext ic;
private Map cache;
private static ServiceLocator serviceLocator;
static {
serviceLocator = new ServiceLocator();
}
private ServiceLocator() {
cacheMap = Collections.synchronizedMap(new HashMap());
}
public InitialContext getInitalContext() throws Exception {
try {
if (ic == null) {
ic = new InitialContext();
}
} catch (Exception e) {
throw e;
}
return ic;
}
public static ServiceLocator getInstance() {
return serviceLocator;
}
public EJBLocalHome getLocalHome(String jndiHomeName) throws Exception {
EJBLoclaHome home = null;
try {
if (cache.containsKey(jndiHomeName)) {
home = (EJBLocalHome)cache.get(jndiHomeName);
} else {
home = (EJBLocalHome)getInitialContext().lookup(jndiHomeName);
cache.put(jndiHomeName, home);
}
} catch (Exception e) {
throw new Exception(e.getMessage());
}
return home;
}
}Spring 프레임워크를 시작하면, Spring Container가 초기화되고, @ComponentScan으로 정의한 Component를 찾아 Bean으로 등록하는 절차를 수행한다.
아래의 캡쳐 사진은 몰라도 되는 Spring — 리플렉션을 이용하는 Spring Container에서 가져왔다.
먼저, Scan을 통해 Bean 타겟을 찾아 BeanDefinition을 정의한다.
이후, org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory 클래스에서 createBeanInstance 생성 메서드를 찾을 수 있다.
실제 Bean을 생성하는 코드는 org.springframework.beans.BeanUtil에 있다.
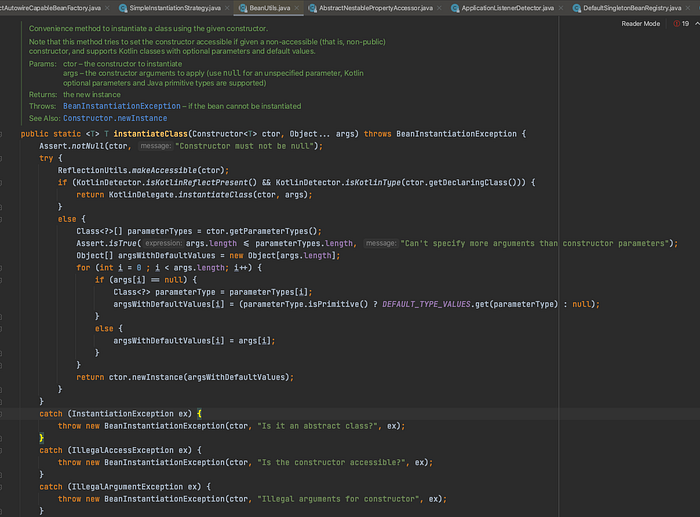
실제 코드가 너무 복잡하니, 간단히 예시를 하나 들어보자. Sample Container를 만든다고 가정하자.
// Inject.java
@Retention(RetentionPolicy.RUNTIME)
public @interface Inject {
}// SampleContainer.java
public class SampleContainer
{
public static <T> T getObject(Class<T> clazz)
{
T instance = createInstance(clazz);
for (Field field : clazz.getDeclaredFields())
{
if (field.getDeclaredAnnotation(Inject.class) != null)
{
Object filedInstance = createInstance(field.getType());
try
{
field.setAccessible(true);
field.set(instance, filedInstance);
}
catch (IllegalAccessException e)
{
throw new RuntimeException("fail to set field", e);
}
}
}
return instance;
}
private static <T> T createInstance(Class<T> clazz)
{
try
{
return clazz.getConstructor().newInstance();
}
catch (InstantiationException | InvocationTargetException | NoSuchMethodException | IllegalAccessException e)
{
throw new RuntimeException("fail to create instance", e);
}
}
}
// SampleComponent.java
public class SampleComponent
{
@Inject
private SampleRepository sampleRepository;
public void doSomething()
{
List<String> results = sampleRepository.findAll();
for (String str : results)
{
System.out.println("result : " + str);
}
}
}
}// SampleRepository.java
public class SampleRepository
{
public List<String> findAll()
{
return Arrays.asList("AA", "BB", "CC");
}
}// Main.java
public class Main{
public static void main(String[] args)
{
SampleComponent sampleComponent = SampleContainer.getObject(SampleComponent.class);
sampleComponent.doSomething();
}
}
위 코드를 잘 보면, SampleContainer에서 SampleComponent 객체를 생성할 때, Reflection을 통해 객체를 생성하고 @Inject로 주입되는 SampleRepository 또한 Reflection으로 넣어주는 것을 알 수 있다.
아래 링크에 가면
singleton으로 관리되는Bean을 생성하기 위한 과정 (ComponentScan -> Bean initialize -> getBean)을 대략적으로 구현한 예시 코드가 있으니 참고하기 바란다. 위 Sample Container 예시도 해당 링크에서 가져왔다.
결론
오늘 내용이 조금 길었다. 결론을 내려보자. Apache Tomcat은 프로세스로 동작한다. Apache는 웹서버고, Tomcat은 ServletContext인데 Apache 하나는 필요에 따라 여러 개의 Tomcat Instances를 가질 수 있다. Tomcat 하나는 Single Servlet이다. Tomcat의 Instance는 각각 Instance마다 Acceptor Thread 한 개가 있고, Dedicated Thread Pool을 보유하고 있다. Tomcat은 기본적으로 one thread per request를 주창하고 있기 때문에, HTTP Request 하나가 들어올 때 하나의 Thread를 배정한다. Request가 종료되면 Thread Pool에 돌려주어 해당 Thread를 재사용할 수 있도록 한다.
Instance 하나는 여러 Thread가 공유하는 ServletContainer를 의미한다. Servlet이 생성될 때, ServletContainer에 이미 만들어지지 않았다면 새로 만든다. Servlet을 이미 만든 적이 있다면, 이를 재사용한다. 그렇기 때문에 Servlet은 재사용이 가능한 형태로 stateless하면서 immutable하게 구현해야 한다. 상태가 없는 객체를 공유하기 때문에 별도의 동기화 과정은 필요하지 않다. 따라서 컨트롤러가 수십회건 수만회건 요청을 받아도 문제가 생기지 않는다.
Servlet의 종류에는 @WebServlet과 Spring @Bean이 있다. 어디서 관리하느냐에 차이다. Tomcat이 관리하냐? Spring이 관리하냐? Bean의 경우에는 POJO와 설정(Configuration Metadata)을 Spring이 제공하는 Container(DI Container, 또는 IoC Container)에 주입시키면 Bean으로 등록되고 사용이 가능하다. 결국 Spring을 쓴다는 것은 Spring으로 Servlet을 다루겠다는 뜻이다. Spring MVC 역시 Servlet Container가 관리하고 있는 Servlet이다.
그래서 Servlet 없이 Spring MVC만 있으면 된다고 하는것은 비지니스 로직을 Spring을 통해 처리하겠다는것이지 Servlet이 필요없다는 얘기가 아니다.
이 내용을 1년 정도 Java Spring을 쓰면서 전혀 깨닫지 못하고 있었다. 기본과 기초가 제일 중요하다는 것을 곱씹어볼 만 하다. 이것도 모른채 WebFlux 공부를 하고 있었으니 말이다. -_- 자바 내부 구현로직을 더 공부해야 겠다는 생각이 든다. 아마 이런 강의?
Other References that has not been aforementioned
- Multiple Processes under one JVM
- Java 시스템 운영 중 알아두면 쓸모 있는 지식들
- How does apache creates a thread?
- Spring MVC 기본 개념
- 서블릿과 서블릿 컨테이너란 무엇인가?
- What is the difference between ApplicationContext and WebApplicationContext in Spring MVC?
- Spring 실행순서
- [Annotation] Servlet Annotation @WebServlet vs @Controller
- THREAD-SAFE하도록 SERVLET작성하기
- [10분 테코톡] 🌻타미의 Servlet vs Spring 또는 코기의 톡
- How Spring Web MVC Really Works — Stackify
- ServletContainer? DI Container? Bean? POJO?