누구나 데이터 파이프라인을 배포할 수 있는 Stackable 소개
Stackable is based on Kubernetes and uses this as the control plane to manage clusters.
Stackable Data Platform는 오픈소스 데이터 관련 오퍼레이터를 쉽게 배포할 수 있는 도구이다. 일반적으로 Stackable은 계층적 구조를 가지고 `airflow-scheduled-job` 이라든지 `data-lakehouse-iceberg` 등과 같은 파이프라인을 베스트 프렉티스로 쉽게 배포할 수 있게 도와주고, Hadoop이나 Kafka, Spark와 같은 데이터를 관리할 수 있는 오픈소스를 설치하고 관리하는 데 필요한 써드파티 의존성을 한 번에 배포할 수 있도록 도와주는 오퍼레이터이다. 우리가 지금까지 살펴본 오퍼레이터들은 각 애플리케이션에 특화된 오퍼레이터였기 때문에, 이렇게 한 번에 묶어준다는 것은 복수 개의 애플리케이션을 연결해야 하는 실무 상황에서 유리할 것으로 보였다.
이 외에도 Grafana와 Prometheus와 같은 모니터링 도구의 배포도 도와주며, ZooKeeper와 OpenSearch 같은 로깅용 라이브러리의 배포도 쉽게 도와준다. 따라서 DevOps 팀이 별도로 사내에 구축되어 있지 않더라도 쉽고 빠르게 배포하여 확인할 수 있는 역할을 수행한다. Stackable이 지원하는 라이브러리로는 Airflow, Druid, HBase, Hadoop HDFS, Hive, Kafka, NiFi, Spark, Superset, Trino, ZooKeeper 등이 있다.
특히 Stackable을 통해 리소스를 배포할 때 문서에서 Operator를 잘 보면 해당 Operator의 아키텍처와 상세 설정 방안 등에 대해 확인 가능하다. 구체적인 정보는 다음 링크에서 확인할 수 있다.
Stackable은 아래 3가지 레이어로 크게 구분할 수 있다.

1. Operators Layer: Stackable에서 배포하고 관리할 수 있는 Data Product들의 개별적인 Operator가 존재한다. 해당 Operator는 `operator` 또는 `release` 와 같은 명령어를 이용하여 설치할 수 있다.
2. Stack Layer: Operators의 상위 계층으로서 데이터 관련 Operator들의 minio나 postgres와 같이 외부 의존성을 같이 사이드카처럼 배포하는 역할을 수행한다. `stack` 명령어를 통해 stack을 설치하고 해당 stack은 release에 의존적이므로 스택을 설치할 때 필요한 릴리즈도 함께 자동으로 설치된다. 따라서 사용자가 릴리스를 관리할 필요 없이 스택을 설치하는 과정에서 필요한 모든 구성 요소들이 자동으로 설정될 수 있다. 예를 들면 쿼리를 수행하는 Trino와 시각화 도구인 Superset을 같이 배포할 수 있는 것이다.
3. Demo Layer: 데이터를 관리할 수 있는 파이프라인을 한 번에 통합적으로 설치하고 관리하는 것을 도와주는 계층이다. Airflow나 ClickHouse, Kafka 등의 파이프라인을 Demo 계층에서 통합적으로 설치할 수 있도록 도와준다. 따라서 https://docs.stackable.tech/home/stable/demos/ 에서 확인할 수 있는 바와 같이 데이터 파이프라인의 베스트 프렉티스 형태의 Config를 한 번에 다운로드 받을 수 있기 때문에 누구나 쉽게 데이터 파이프라인을 쉽게 구축하고 관리할 수 있다.
Stackable 배포 실습
- 이전의 실습 환경과 달리 Ubuntu 22.04에서 실습한다. 이러한 이유는 AMI에서는 stackable이 설정이 어렵다고 알려져 있기 때문이다. 워커 노드는 c5.2xlarge를 사용하고, 기존의 텍스트에디터로 사용했던 cat 대신 batcat을 사용할 것이다.

- Stackable 배포 준비
# 배포 전 실습 환경 정보 확인 kubectl get node - label-columns=node.kubernates.io/instance-type
# 각 node IP를 변수로 저장해서 사용하기 쉽게 함
N1=$(kubectl get node - label-columns=topology.kubernetes.io/zone - selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node - label-columns=topology.kubernetes.io/zone - selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node - label-columns=topology.kubernetes.io/zone - selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
# eksctl host에서 노드에 접속 가능하게 룰 설정
NGSGID=$(aws ec2 describe-security-groups - filters Name=group-name,Values='*ng1*' - query "SecurityGroups[*].[GroupId]" - output text) aws ec2 authorize-security-group-ingress - group-id $NGSGID - protocol '-1' - cidr 192.168.1.100/322. 각 노드에 Private IP를 배분하고 파드에 접속 가능하도록 관련 룰을 추가한다. 로드 밸런서를 설치하기 위하여 아래 커맨드를 보시면 EKS Helm Chart를 가져오고 현재 사용 중인 클러스터에서 기존의 Service Account의 이름을 바꾸어서 설치한다.
# loadbalancer 설치
helm repo add eks https://aws.github.io/eks-charts
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system - set clusterName=$CLUSTER_NAME \ - set serviceAccount.create=false - set serviceAccount.name=aws-load-balancer-controller3. EBS gp3 스토리지 클래스와 EFS 스토리지 클래스를 생성한다.
# ebs gp3 storage class 생성 : 파일시스템 xfs
kubectl patch sc gp2 -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
kubectl apply -f https://raw.githubusercontent.com/gasida/DOIK/main/1/gp3-sc-xfs.yaml
# efs storage class
cat <<EOT > efs-sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: $EFS_ID
directoryPerms: "700"
EOT
kubectl apply -f efs-sc.yaml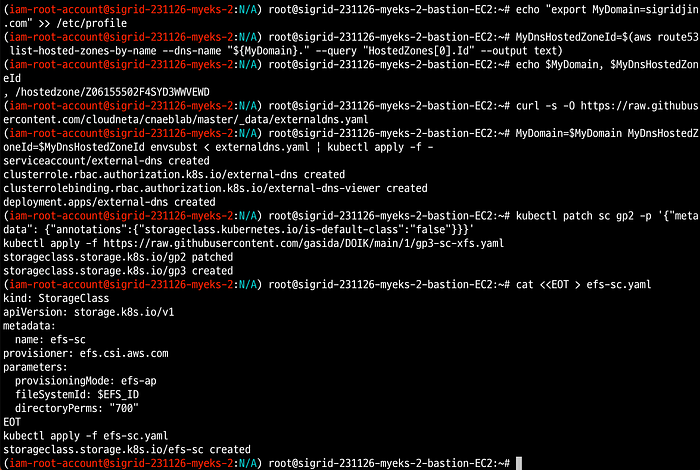
4. Stackable Endpoint에서 원하는 IP로 접속이 가능하도록 보안 그룹에 현재 SSH로 접속한 IP를 추가해준다.
# 워커노드의 '#-nodegroup-ng1-remoteAccess' 보안 그룹에 자신의 집 공인IP 접속 허용 추가
NGSGID=$(aws ec2 describe-security-groups - filters Name=group-name,Values='*ng1*' - query "SecurityGroups[*].[GroupId]" - output text)
aws ec2 authorize-security-group-ingress - group-id $NGSGID - protocol '-1' - cidr $(curl -s ipinfo.io/ip)/32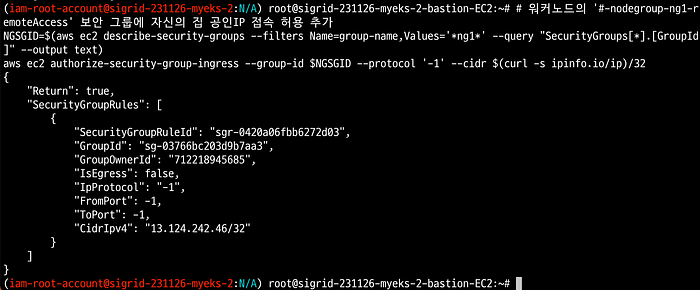
5. Stackable을 배포한다. 프로비저닝해둔 EKS에 Stackable을 설치한다. 따라서 바이너리를 설치하고 해당 명령어로 배포하면 된다. 우리가 설치할 버전은 stackable ver 1.0.0이다.
# stackablectl download
curl -L -o stackablectl https://github.com/stackabletech/stackable-cockpit/releases/download/stackablectl-1.0.0-rc3/stackablectl-x86_64-unknown-linux-gnu #allow execution of stackablectl
chmod +x stackablectl mv stackablectl /usr/local/bin stackablectl -h
stackablectl -V
# 자동완성 추가 wget https://raw.githubusercontent.com/stackabletech/stackable-cockpit/main/extra/completions/stackablectl.bash mv stackablectl.bash /etc/bash_completion.d/
# 제공하는 오퍼레이터를 확인한다
stackablectl operator list
# 제공되는 스택을 확인한다
stackablectl stack list
# 제공되는 데모인 stackable release 설치해서 스택을 구성하고 데이터를 구성해본다.
stackablectl demo list
StackableList Trino-Taxi-Data 데이터셋
- 우리가 배포하고자 하는 아키텍처는 하기와 같다.
1. Superset: 데이터 시각화 도구인데, 해당 데모에서는 Trino를 이용한 SQL 쿼리 결과를 대시보드에서 확인하기 위하여 사용된다.
2. Trino: 분산형 SQL 쿼리 엔진으로서 SQL 쿼리를 분산해서 빠르게 결과를 반환받는데 쓴다.
3. MinIO: S3-compatible한 Object Storage 플랫폼이고, 해당 데모에서는 모든 사용 데이터를 저장하기 위하여 사용된다.
4. Hive Metastore: Apache Hive와 다른 서비스들의 메타데이터를 저장하는 서비스로, 해당 데모에서는 Trino의 메타데이터를 저장하기 위하여 사용된다.
5. Open Policy Agent (OPA): 클라우드 네이티브 환경에서 Stack 전반에 걸쳐 Policy를 통합하는 범용 Policy Engine이다. 이번 데모에서는 Trino의 권한 부여자로 사용되며 어떤 사용자가 어떤 데이터를 쿼리할 수 있는 지 결정하게 된다.
- 우리가 배포하려고 하는 [데이터셋](https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page)은 2.5년 동안의 뉴욕 택시 데이터를 S3 Bucket으로 가져온다음 Trino Hivestore를 만들어 쿼리 결과를 Superset 대시보드에 반영하는 예제이다.
- 데모의 정보를 확인하자.
stackablectl demo list
stackablectl demo list -o json | jq
stackablectl demo describe trino-taxi-data
Demo trino-taxi-data Description Demo loading 2.5 years of New York taxi data into S3 bucket, creating a Trino table and a Superset dashboard Documentation https://docs.stackable.tech/stackablectl/stable/demos/trino-taxi-data.html Stackable stack trino-superset-s3 Labels trino, superset, minio, s3, ny-taxi-data2. 데모를 수행해보자.
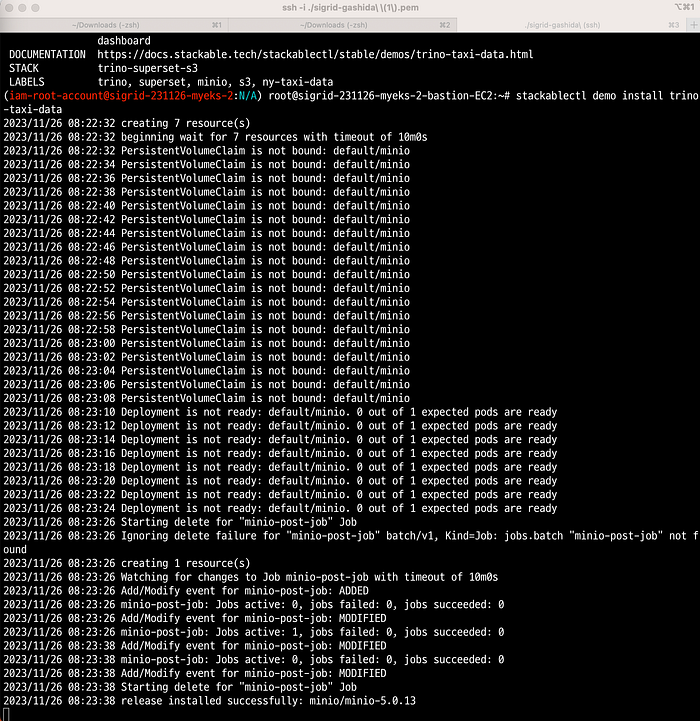
# [터미널] 모니터링
## Stackable을 통해 배포되는 파드, pvc, job, svc 를 확인해 봅니다.
watch -d "kubectl get pod -n stackable-operators;echo;kubectl get pod,job,svc,pvc"
# 데모 설치 : 데이터셋 다운로드 job 포함 8분 정도 소요
stackablectl demo install trino-taxi-data
# 설치 확인
## Stackable 또한 크게는 helm chart로 각 데이터 product를 설치하는데 사용하게 됩니다.
helm list -n stackable-operators
helm list
kubectl top node
kubectl top pod -A
kubectl get-all -n default
kubectl get deploy,sts,pod
kubectl get job
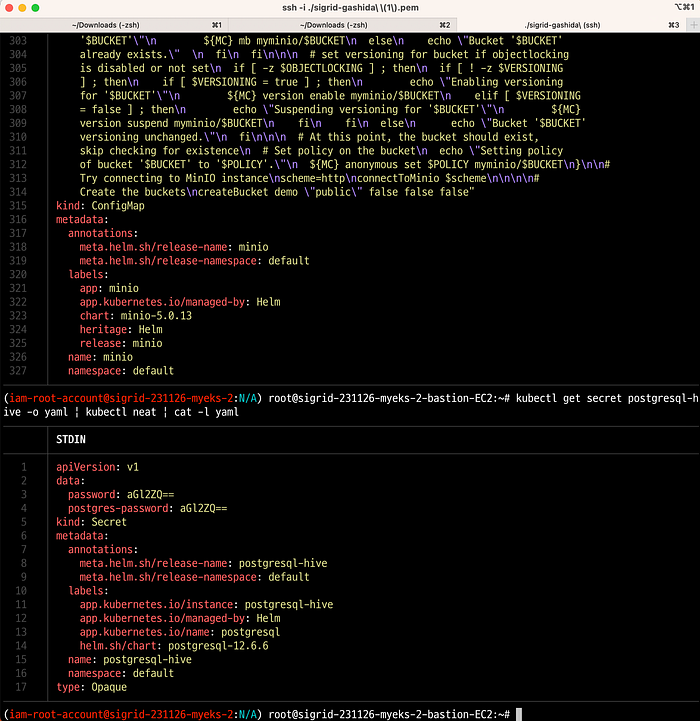
kubectl get job load-ny-taxi-data -o yaml | kubectl neat | cat -l yaml
kubectl get job create-ny-taxi-data-table-in-trino -o yaml | kubectl neat | cat -l yaml
kubectl get job setup-superset -o yaml | kubectl neat | cat -l yaml
kubectl get job superset -o yaml | kubectl neat | cat -l yaml
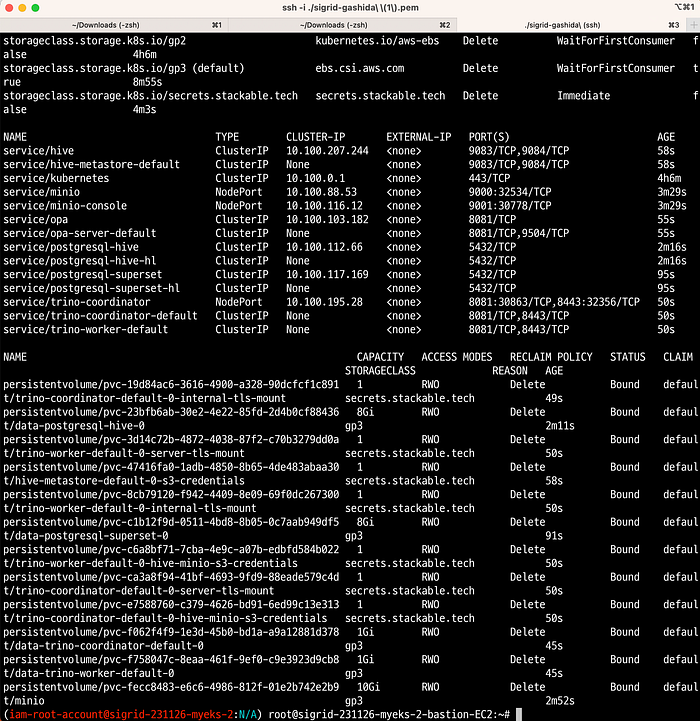
## Stackable은 secrets.stackable.tech 라는 storageClass도 같이 배포되는데, 여기에 값이 노출되면 안되는(계정정보 등) 값들이 저장되게 됩니다.
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
efs-sc efs.csi.aws.com Delete Immediate false 71m
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 109m
gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 72m
secrets.stackable.tech secrets.stackable.tech Delete Immediate false 23m
## pvc나 pv를 확인해보면, 특정 리소스들은 secrets.stackable.tech storageclass에 저장되는것을 확인할 수 있습니다.
kubectl get sc,pvc,pv
kubectl get pv |grep gp3
kubectl get sc secrets.stackable.tech -o yaml | kubectl neat | cat -l yaml
kubectl df-pv
kubectl get svc,ep,endpointslices
kubectl get cm,secret
## 설치되는 서드파티 서비스(minio, hive, 등) 에 대한 config들은, configmap에 저장되게 됩니다.
kubectl get cm minio -o yaml | kubectl neat | cat -l yaml
kubectl describe cm minio
kubectl get cm hive-metastore-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm hive -o yaml | kubectl neat | cat -l yaml
kubectl get cm postgresql-hive-extended-configuration -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-coordinator-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-coordinator-default-catalog -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-worker-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-worker-default-catalog -o yaml | kubectl neat | cat -l yaml
kubectl get cm create-ny-taxi-data-table-in-trino-script -o yaml | kubectl neat | cat -l yaml
kubectl get cm superset-node-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm superset-init-db -o yaml | kubectl neat | cat -l yaml
kubectl get cm setup-superset-script -o yaml | kubectl neat | cat -l yaml
## 설치되는 서드파티 서비스(minio, hive, 등) 에 대한 secret들은, secret에 저장되게 됩니다.
kubectl get secret minio -o yaml | kubectl neat | cat -l yaml
kubectl get secret minio-s3-credentials -o yaml | kubectl neat | cat -l yaml
kubectl get secret postgresql-hive -o yaml | kubectl neat | cat -l yaml
kubectl get secret postgresql-superset -o yaml | kubectl neat | cat -l yaml
kubectl get secret trino-users -o yaml | kubectl neat | cat -l yaml
kubectl get secret trino-internal-secret -o yaml | kubectl neat | cat -l yaml
kubectl get secret superset-credentials -o yaml | kubectl neat | cat -l yaml
kubectl get secret superset-mapbox-api-key -o yaml | kubectl neat | cat -l yaml
## Stackable의 crd list
$ kubectl get crd | grep stackable
authenticationclasses.authentication.stackable.tech 2023-11-25T23:21:05Z
druidconnections.superset.stackable.tech 2023-11-25T23:22:00Z
hiveclusters.hive.stackable.tech 2023-11-25T23:21:22Z
opaclusters.opa.stackable.tech 2023-11-25T23:21:38Z
s3buckets.s3.stackable.tech 2023-11-25T23:21:05Z
s3connections.s3.stackable.tech 2023-11-25T23:21:05Z
secretclasses.secrets.stackable.tech 2023-11-25T23:21:55Z
supersetclusters.superset.stackable.tech 2023-11-25T23:22:00Z
supersetdbs.superset.stackable.tech 2023-11-25T23:22:00Z
trinocatalogs.trino.stackable.tech 2023-11-25T23:22:15Z
trinoclusters.trino.stackable.tech 2023-11-25T23:22:15Z
## Stackable의 cr list
kubectl explain trinoclusters
kubectl describe trinoclusters.trino.stackable.tech
kubectl get hivecluster,opacluster,s3connection
kubectl get supersetcluster,supersetdb
kubectl get trinocluster,trinocatalog
kubectl get hivecluster -o yaml | kubectl neat | cat -l yaml
kubectl get s3connection -o yaml | kubectl neat | cat -l yaml
kubectl get supersetcluster -o yaml | kubectl neat | cat -l yaml
kubectl get supersetdb -o yaml | kubectl neat | cat -l yaml
kubectl get trinocluster -o yaml | kubectl neat | cat -l yaml
kubectl get trinocatalog -o yaml | kubectl neat | cat -l yaml
# 배포 스택 정보 확인 : 바로 확인 하지 말고, 설치 완료 후 아래 확인 할 것 - Endpoint(접속 주소 정보), Conditions(상태 정보)
$ stackablectl stacklet list
# 배포 스택의 product 접속 계정 정보 확인 : 대부분 admin / adminadmin 계정 정보 사용
stackablectl stacklet credentials superset superset
stackablectl stacklet credentials minio minio-console # 계정 정보가 출력되지 않음
# 배포 오퍼레이터 확인
$ stackablectl operator installed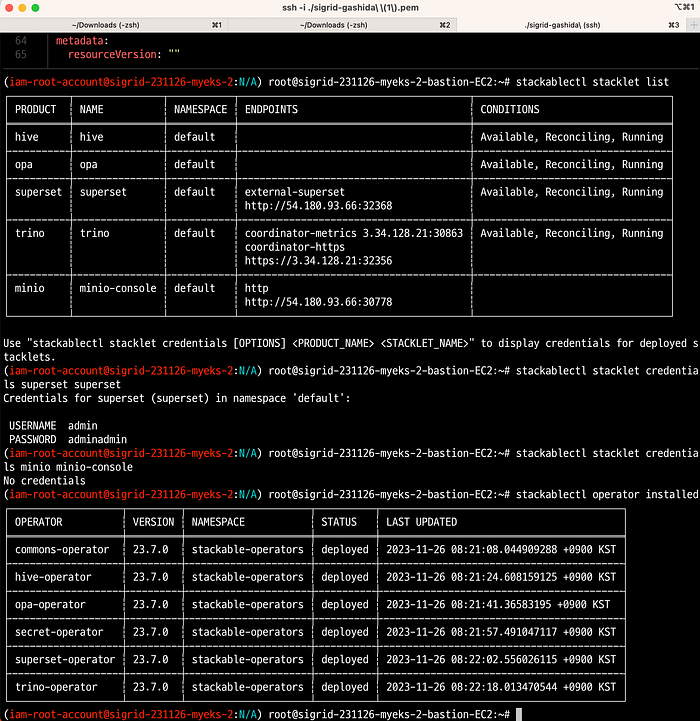
3. Minio에 접근한다.
- Stackable Demo를 배포할 때
load-ny-taxi-datajob이라는 특정 batch Job이 돌면서 curl로 가져와서 minio에 적재하였음
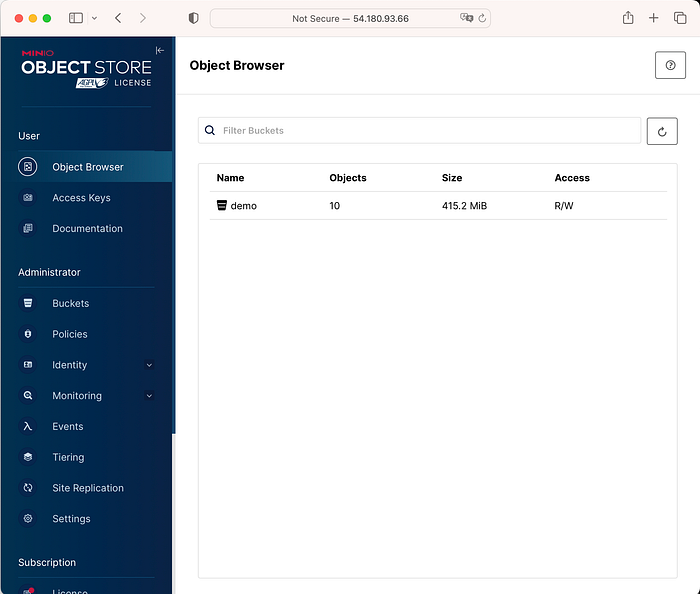
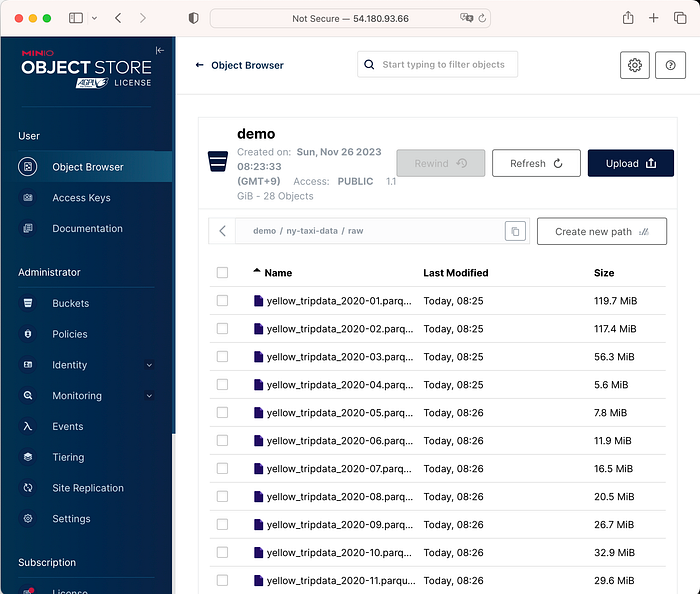
3. 데모의 결과값을 확인한다.
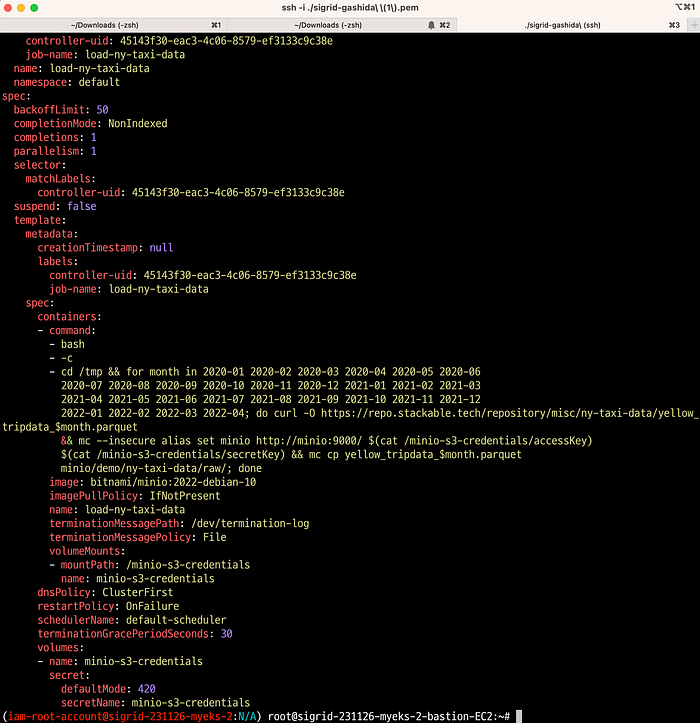
$ kubectl get job load-ny-taxi-data -o yaml | kubectl neat | cat -l yaml -p
apiVersion: batch/v1
kind: Job
metadata:
annotations:
batch.kubernetes.io/job-tracking: ""
labels:
controller-uid: 17c8b4af-0c2a-4451-aa4f-a0d65e169676
job-name: load-ny-taxi-data
name: load-ny-taxi-data
namespace: default
spec:
backoffLimit: 50
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
controller-uid: 17c8b4af-0c2a-4451-aa4f-a0d65e169676
suspend: false
template:
metadata:
creationTimestamp: null
labels:
controller-uid: 17c8b4af-0c2a-4451-aa4f-a0d65e169676
job-name: load-ny-taxi-data
spec:
containers:
- command:
- bash
- -c
- cd /tmp && for month in 2020-01 2020-02 2020-03 2020-04 2020-05 2020-06
2020-07 2020-08 2020-09 2020-10 2020-11 2020-12 2021-01 2021-02 2021-03
2021-04 2021-05 2021-06 2021-07 2021-08 2021-09 2021-10 2021-11 2021-12
2022-01 2022-02 2022-03 2022-04; do curl -O https://repo.stackable.tech/repository/misc/ny-taxi-data/yellow_tripdata_$month.parquet # curl로 다운로드 받음
&& mc --insecure alias set minio http://minio:9000/ $(cat /minio-s3-credentials/accessKey) # minio 버킷에 복사 저장
$(cat /minio-s3-credentials/secretKey) && mc cp yellow_tripdata_$month.parquet
minio/demo/ny-taxi-data/raw/; done
image: bitnami/minio:2022-debian-10
imagePullPolicy: IfNotPresent
name: load-ny-taxi-data
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /minio-s3-credentials
name: minio-s3-credentials
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
schedulerName: default-scheduler
terminationGracePeriodSeconds: 30
volumes:
- name: minio-s3-credentials
secret:
defaultMode: 420
secretName: minio-s3-credentials해당 데모는 4개의 Job이 존재한다.

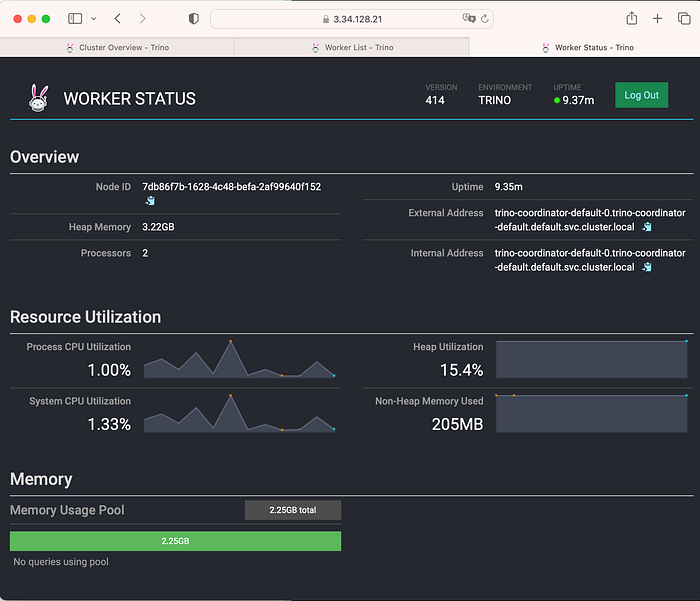
4. Trino에 접속해보고 Active Workers를 확인해본다.
Trino의 Config를 확인한다.
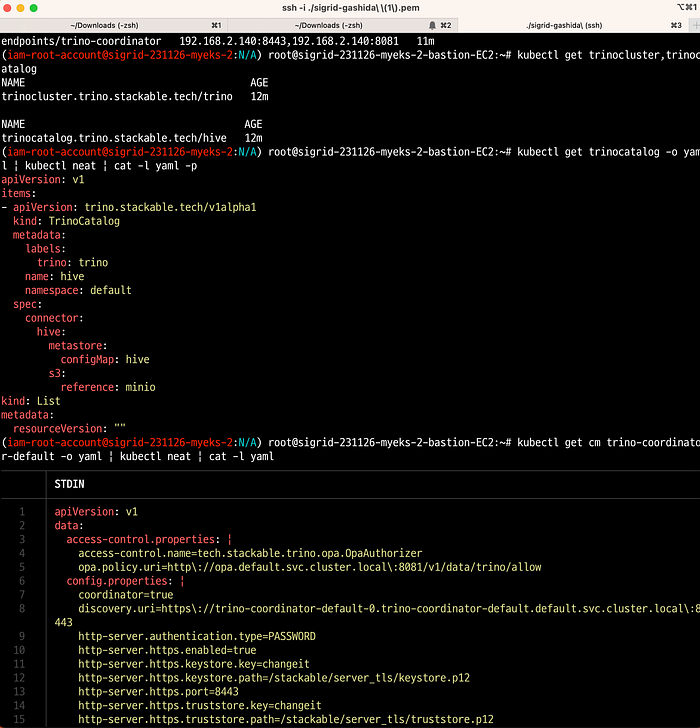
# trino의 svc,ep를 확인합니다.
kubectl get svc,ep trino-coordinator
# trino측 job을 확인합니다.
kubectl get job create-ny-taxi-data-table-in-trino -o yaml | kubectl neat | cat -l yaml
kubectl get trinocluster,trinocatalog
kubectl get trinocluster -o yaml | kubectl neat | cat -l yaml -p
kubectl get trinocatalog -o yaml | kubectl neat | cat -l yaml -p
...
spec:
connector: # Hive와 Minio를 연결하는 부분
hive:
metastore:
configMap: hive
s3:
reference: minio
...
kubectl get cm trino-coordinator-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-coordinator-default-catalog -o yaml | kubectl neat | cat -l yaml -p
...
data:
hive.properties: | # hive properties
connector.name=hive
hive.metastore.uri=thrift\://hive-metastore-default-0.hive-metastore-default.default.svc.cluster.local\:9083
hive.s3.aws-access-key=${ENV\:CATALOG_HIVE_HIVE_S3_AWS_ACCESS_KEY} # minio accesskey
hive.s3.aws-secret-key=${ENV\:CATALOG_HIVE_HIVE_S3_AWS_SECRET_KEY} # minio secret key
hive.s3.endpoint=http\://minio\:9000
hive.s3.path-style-access=true
hive.s3.ssl.enabled=false
hive.security=allow-all
...
# configmap을 확인해봅니다.
kubectl get cm trino-worker-default -o yaml | kubectl neat | cat -l yaml
kubectl get cm trino-worker-default-catalog -o yaml | kubectl neat | cat -l yaml
kubectl get cm create-ny-taxi-data-table-in-trino-script -o yaml | kubectl neat | cat -l yaml
# trino 관련 secret을 확인합니다.
kubectl get secret trino-users -o yaml | kubectl neat | cat -l yaml
kubectl get secret trino-internal-secret -o yaml | kubectl neat | cat -l yaml
kubectl logs -n stackable-operators -l app.kubernetes.io/instance=trino-operator -f
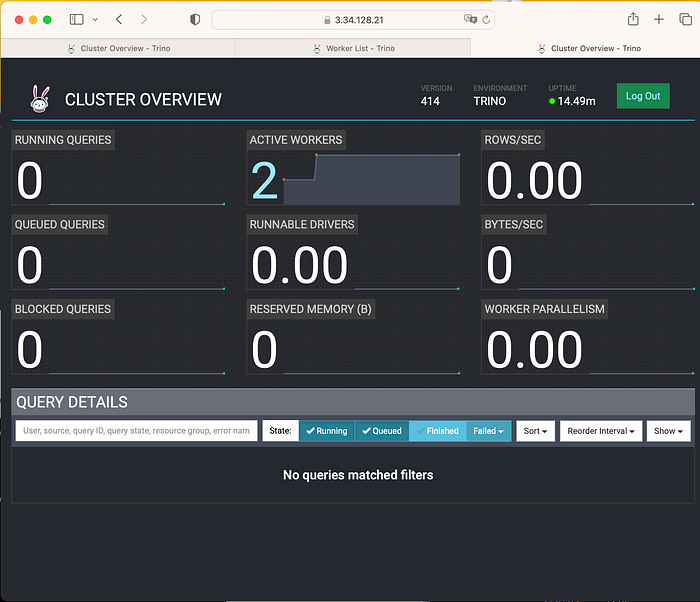
5. Trino의 worker를 2대로 증설해보자.
kubectl get trinocluster trino -o json | cat -l json -p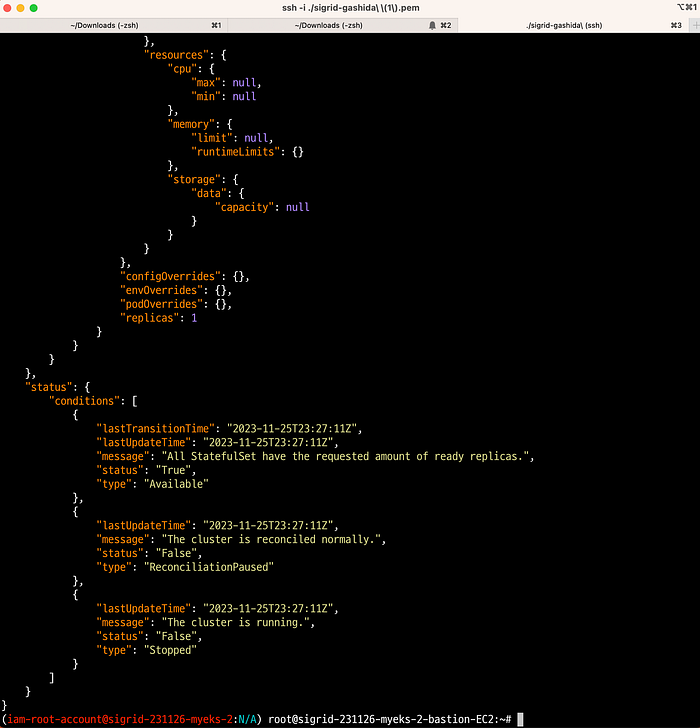
kubectl patch trinocluster trino --type='json' -p='[{"op": "replace", "path": "/spec/workers/roleGroups/default/replicas", "value":2}]'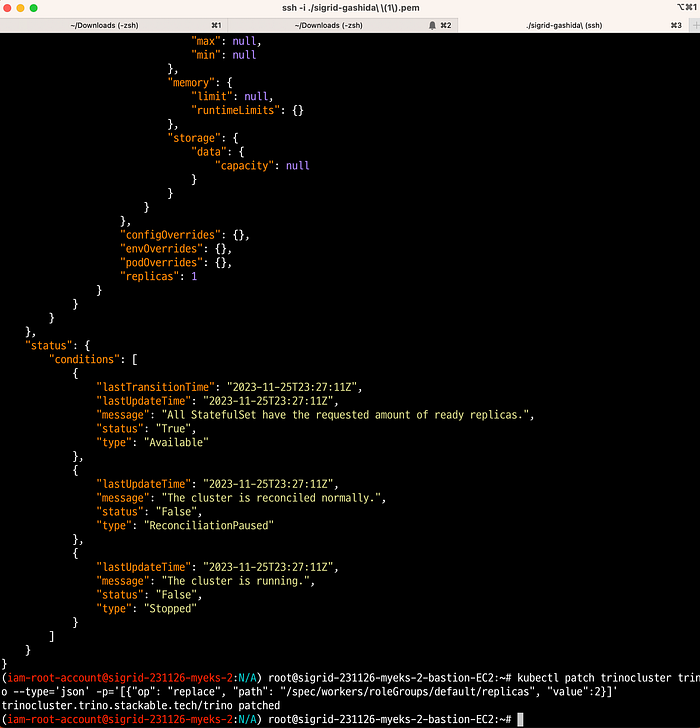
이제 Trino의 UI 상에서 worker 증설을 확인할 수 있다.
6. Superset의 Web UI에 접속해보자. 우리가 이전에 받았던 Taxi data를 확인할 수 있다.

7. Taxi data dashboard를 클릭해서 Trino를 확인하면 쿼리를 수행하는 모습을 볼 수 있다. Trino의 Active Worker가 여러 개라면 해당 쿼리가 병렬로 수행되어 빠르게 결과를 가져올 수 있다.

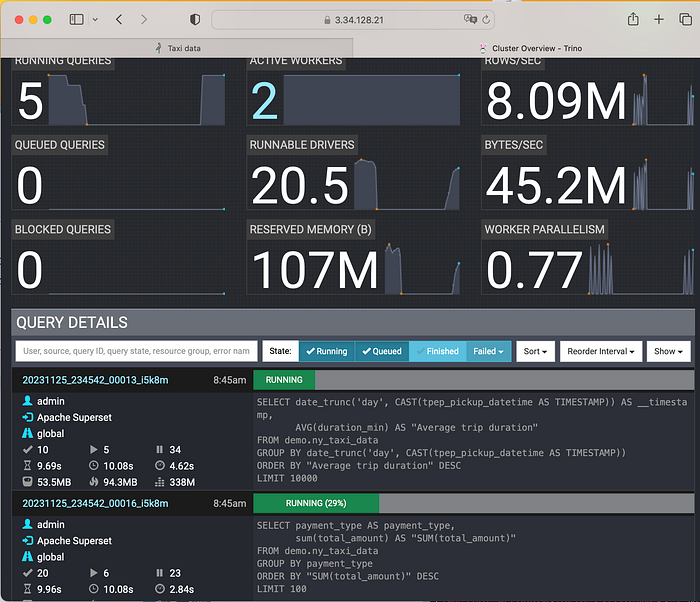
SQL Lab에서 다음과 같이 질의할 수 있다. AWS Athena를 연상시킨다.
- 아래와 같이 설정한다.
- schema : demo
- SEE TABLE SCHEMA : ny_taxi_data
select
format_datetime(tpep_pickup_datetime, 'YYYY/MM') as month,
count(*) as trips,
sum(total_amount) as sales,
avg(duration_min) as avg_duration_min
from ny_taxi_data
group by 1
order by 1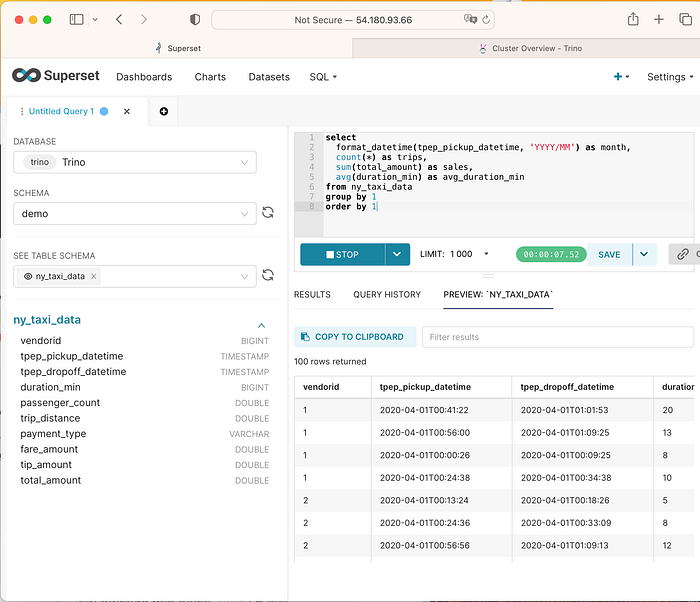
8. 아래의 명령어를 이용하여 자원을 삭제한다.
# Demo layer
kubectl delete supersetcluster,supersetdb superset
kubectl delete trinocluster trino && kubectl delete trinocatalog hive
kubectl delete hivecluster hive
kubectl delete s3connection minio
kubectl delete opacluster opa
# Demo로 생성된 리소스 제거
helm uninstall postgresql-superset
helm uninstall postgresql-hive
helm uninstall minio
# Demo로 생성된 리소스 제거
kubectl delete job --all
kubectl delete pvc --all
#
kubectl delete cm create-ny-taxi-data-table-in-trino-script setup-superset-script trino-opa-bundle
kubectl delete secret minio-s3-credentials secret-provisioner-tls-ca superset-credentials superset-mapbox-api-key trino-users
kubectl delete sa superset-sa
# operator layer 삭제
stackablectl operator uninstall superset trino hive secret opa commons
# 남은 리소스 확인
kubectl get-all -n stackable-operatorsZooKeeper와 Kafka를 Stackable로 배포해보자
먼저 -i option으로 배포하기를 원하는 Stackable의 Operator를 설치 가능하다. Operator는 release에 종속적이기 때문에, release를 명령어 뒤에 지정해야 한다.
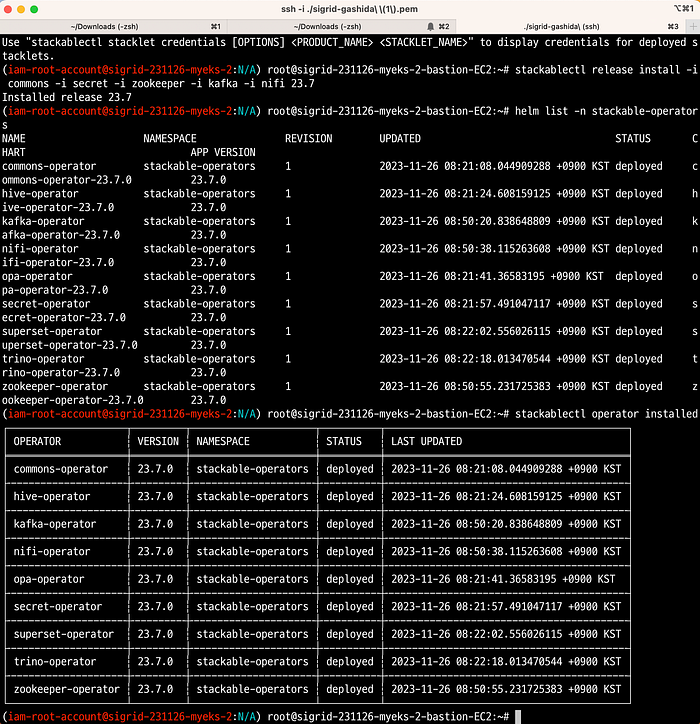
# [터미널1] 모니터링
watch -d "kubectl get pod -n stackable-operators"
# [터미널2] 설치
stackablectl release list
## -i 옵션으로 설치할 오퍼레이터를 지정, 맨뒤에 릴리즈 지정
stackablectl release install -i commons -i secret -i zookeeper -i kafka -i nifi 23.7
[INFO ] Installing release 23.7
[INFO ] Installing commons operator in version 23.7.0
[INFO ] Installing kafka operator in version 23.7.0
[INFO ] Installing nifi operator in version 23.7.0
[INFO ] Installing secret operator in version 23.7.0
[INFO ] Installing zookeeper operator in version 23.7.0
# 설치 확인
helm list -n stackable-operators
stackablectl operator installed
## 설치완료된 crd 확인
kubectl get crd | grep stackable.tech
kubectl get podStackable의 operator를 통해 같이 설치된 crd로 zookeeper 리소스를 관리해보자. 이제 Stackable의 crd로 zookeeper를 배포해보자.

kubectl apply -f - <<EOF
---
apiVersion: zookeeper.stackable.tech/v1alpha1 # stackable zookeeper crd
kind: ZookeeperCluster
metadata:
name: simple-zk # name
spec:
image:
productVersion: "3.8.1"
stackableVersion: "23.7"
clusterConfig:
tls:
serverSecretClass: null
servers:
roleGroups:
primary:
replicas: 1 # zookeeper cluster 개수
config:
myidOffset: 10
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-zk-znode
spec:
clusterRef:
name: simple-zk
EOF설치 여부를 확인해본다.
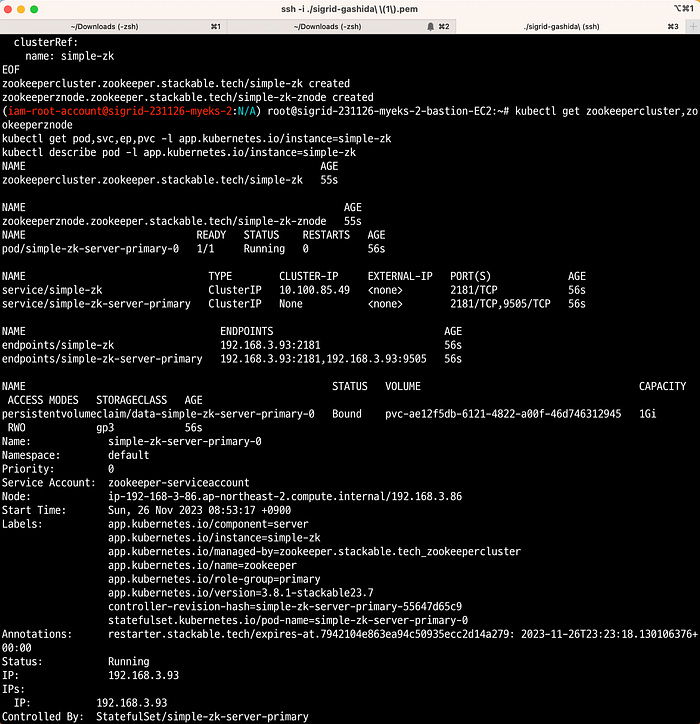
이제 Stackable의 CRD로 Kafka를 설치해보자.
kubectl apply -f - <<EOF
---
apiVersion: kafka.stackable.tech/v1alpha1 # stackable kafka crd
kind: KafkaCluster
metadata:
name: simple-kafka
spec:
image:
productVersion: "3.4.0"
stackableVersion: "23.7"
clusterConfig:
zookeeperConfigMapName: simple-kafka-znode
tls:
serverSecretClass: null
brokers:
roleGroups:
brokers:
replicas: 3 # broker 개수
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-kafka-znode
spec:
clusterRef:
name: simple-zk
namespace: default
EOFKafka가 정상 설치되었는지 확인해본다.
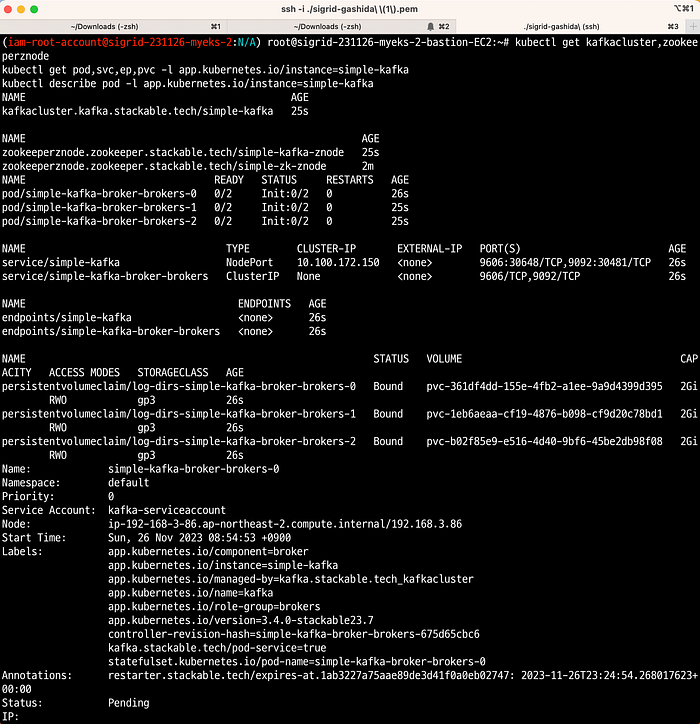
Apache Nifi를 설치해본다.
NiFi는 미국 국가안보국(NSA)에서 Apache에 기증한 dataflow 엔진입니다. 기본적으로 데이터를 Extract, Transformation, Load (ETL)할 수 있는 툴로써 UI를 통해 다양한 기능들을 통해 데이터들을 flow화 시킬 수 있습니다. 그리고 가장 큰 특징으로는 클러스터를 구성해서 데이터를 처리할 수 있습니다.
kubectl apply -f - <<EOF
---
apiVersion: zookeeper.stackable.tech/v1alpha1 # stackable zookeeper crd
kind: ZookeeperZnode
metadata:
name: simple-nifi-znode
spec:
clusterRef:
name: simple-zk
---
apiVersion: v1
kind: Secret
metadata:
name: nifi-admin-credentials-simple
stringData:
username: admin
password: AdminPassword
---
apiVersion: nifi.stackable.tech/v1alpha1 # stackable nifi crd
kind: NifiCluster
metadata:
name: simple-nifi
spec:
image:
productVersion: "1.21.0"
stackableVersion: "23.7"
clusterConfig:
listenerClass: external-unstable
zookeeperConfigMapName: simple-nifi-znode
authentication:
method:
singleUser:
adminCredentialsSecret: nifi-admin-credentials-simple
sensitiveProperties:
keySecret: nifi-sensitive-property-key
autoGenerate: true
nodes:
roleGroups:
default:
replicas: 1
EOFNifi의 정상 배포 여부를 확인해본다.
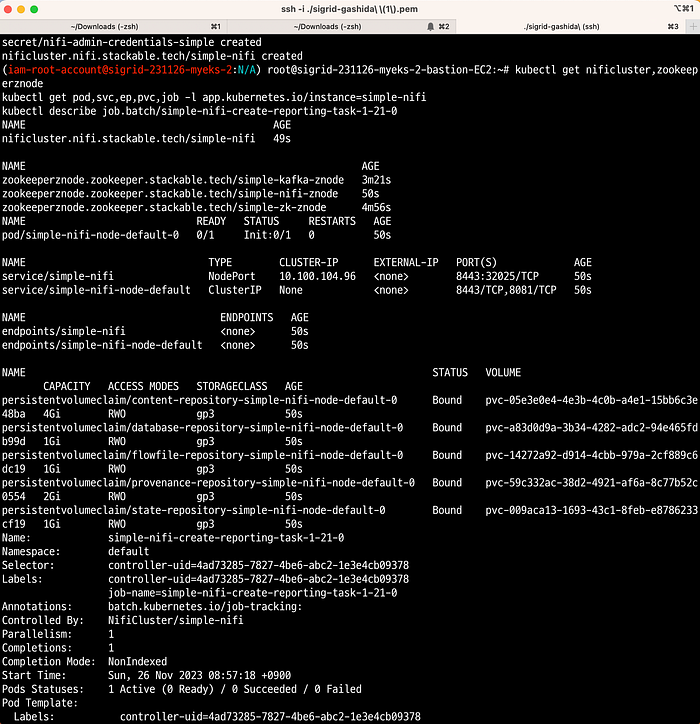
이제 배포된 서비스를 테스트해본다.
# 설치된 정보 확인
$ stackablectl stacklet list
# ZooKeeper의 클러스터 정보 확인
$ kubectl exec -i -t simple-zk-server-primary-0 -c zookeeper -- bin/zkCli.sh
$ [zk: localhost:2181(CONNECTED) 0] ls /
# Kafka로 토픽을 생성해서 확인
# 토픽 생성
kubectl exec -it simple-kafka-broker-brokers-0 -c kafka -- bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic demo
...
Created topic demo.
...
# 토픽 확인
kubectl exec -it simple-kafka-broker-brokers-0 -c kafka -- bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
...
demo
...
# 토픽에 메세지 프로듀싱 (10개)
for ((i=1; i<=10; i++)); do echo "test-$i" ; kubectl exec -it simple-kafka-broker-brokers-0 -c kafka -- sh -c "echo test1-$i | bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic demo" ; date ; done
# Nifi에 접속해서 정상 동작 확인
# NiFi admin 계정의 암호 확인
kubectl get secrets nifi-admin-credentials-simple -o jsonpath="{.data.password}" | base64 -d && echo
AdminPassword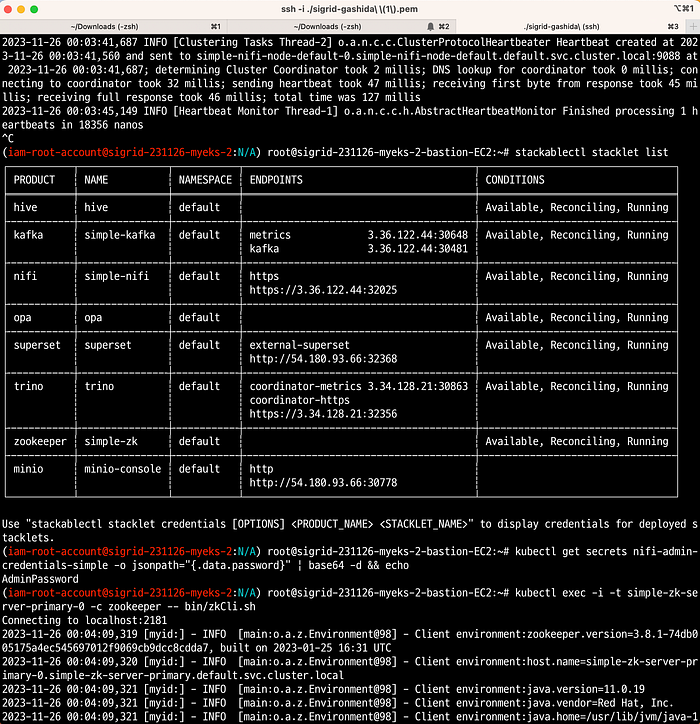
마지막으로 배포된 서비스를 삭제하여 실습을 종료해본다.
# Apache NiFi 삭제
kubectl delete nificluster simple-nifi && kubectl delete zookeeperznode simple-nifi-znode
# kafka-ui 삭제
helm uninstall kafka-ui
# Apache kafka 삭제
kubectl delete kafkacluster simple-kafka && kubectl delete zookeeperznode simple-kafka-znode
# Apache ZooKeeper 삭제
kubectl delete zookeepercluster simple-zk && kubectl delete zookeeperznode simple-zk-znode
# secret, pvc 삭제
kubectl delete secret nifi-admin-credentials-simple nifi-sensitive-property-key secret-provisioner-tls-ca
kubectl delete pvc --all
# operator 삭제
stackablectl operator uninstall nifi kafka zookeeper secret commons
# 남은 리소스 확인
kubectl get-all -n stackable-operators다음 시간에는 Airflow Operator를 배포해보도록 하겠다.
