Understanding Basic Concepts of Kubernetes
The first-week note on gashida’s PKOS study
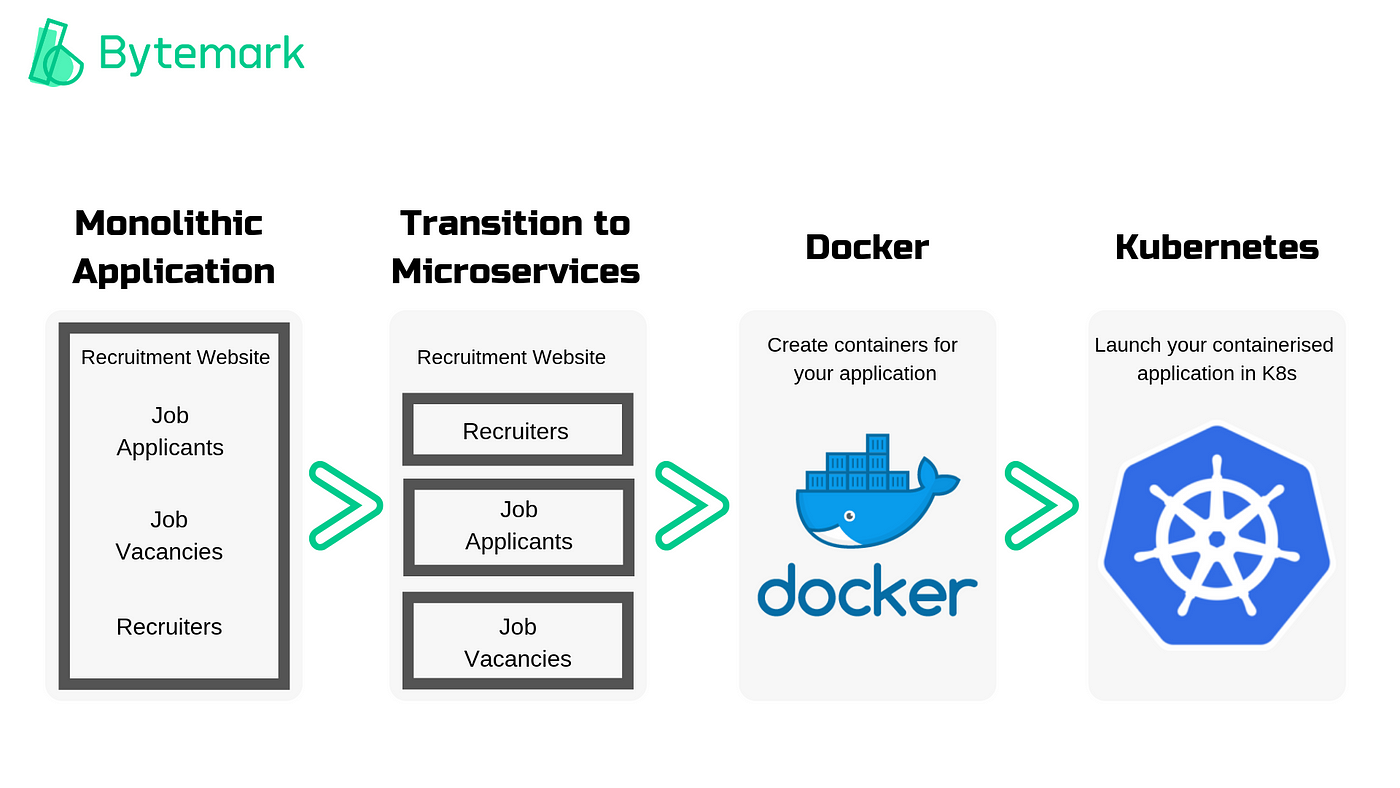
Background — You need Kubernetes, it definitely
I have recently developed an interest in getting my hands dirty with microservices architecture when building backend servers. The architecture has been touted considerably by tech magnates while having evolved over many years, moving from the basic concept to more complex design patterns and related infrastructure platforms. A good example is the size of services—there has been an increase in the number of small services that only require 1 or 2 CPU cores to run. Considering the fact that the difficulty of operating and deploying multiple images in a single VM environment while managing the large size of the VM images is not efficient for small-sized services.
Then what logic brings us to consider Kubernetes — k8s — in the first place? Docker containers are amazing in that they provide an easy way to package and deploy services, allow for process isolation, efficient resource utilization, and more. However, when it comes to running containers at the production level, it ends up dealing with dozens and thousands of containers over time. The doomed future would make you grapple with managing the containers, especially when integrating and orchestrating the modular parts, scaling up and down based on demand dynamically, providing communication across clusters and more.
You need Kubernetes, which sits on top of all containers. The tool works as a container scheduler. Granted that you don’t have only a few containers, it is clearly burdensome work to decide where to place each container. Scheduling tackles the problem at this point — when deploying containers on machines with 16 CPUs and 32GB of memory, the size of the containers should be varied, and it is crucial to place the containers in the appropriate condition depending on the characteristics of the application. For better performance, it may be necessary to keep containers on servers that are in the same physical location, while at other times it might be crucial to spread the containers out across different servers to ensure the availability of the application.
Kubernetes also enables you to specify the desired state of your clusters through declarative expressions (like YAML files) rather than through the execution of prompt deployment scripts. This means that a scheduler can keep an eye on the cluster all the time and do something when the actual state is different from the desired state. The scheduler acts like an operator — constantly monitoring the system and rectifying any discrepancies between the desired and actual states.
All in all, Kubernetes is batteries-included for orchestrating containers and will act as a guide to assist you in ensuring that the correct resources are assigned to the appropriate containers.
Pets and Cattle — The Ideology for the tool’s philosophy
Pets — Servers or server pairs that are treated as indispensable or unique systems that can never be down. Typically they are manually built, managed, and “hand fed”. Examples include mainframes, solitary servers, HA loadbalancers/firewalls (active/active or active/passive), database systems designed as master/slave (active/passive), and so on.
Cattle — Arrays of more than two servers, that are built using automated tools, and are designed for failure, where no one, two, or even three servers are irreplaceable. Typically, during failure events no human intervention is required as the array exhibits attributes of “routing around failures” by restarting failed servers or replicating data through strategies like triple replication or erasure coding. Examples include web server arrays, multi-master datastores such as Cassandra clusters, multiple racks of gear put together in clusters, and just about anything that is load-balanced and multi-master. — Cloud Scaling
The Kubernetes team borrowed the analogy of “pets and cattle” to explain the philosophy of the orchestration tool in a blog post in 2016. The analogy is used to describe the stark differences in how infrastructure is treated and managed. In the "pets" model, servers are cared for and protected as if they were unique and valuable assets. However, in the “cattle” model, servers are treated as interchangeable but dispensable resources that can be easily replaced if they go down. The latter model is more efficient and resilient in that it is easily applicable in cloud-based environments and microservices architecture.
The Cluster
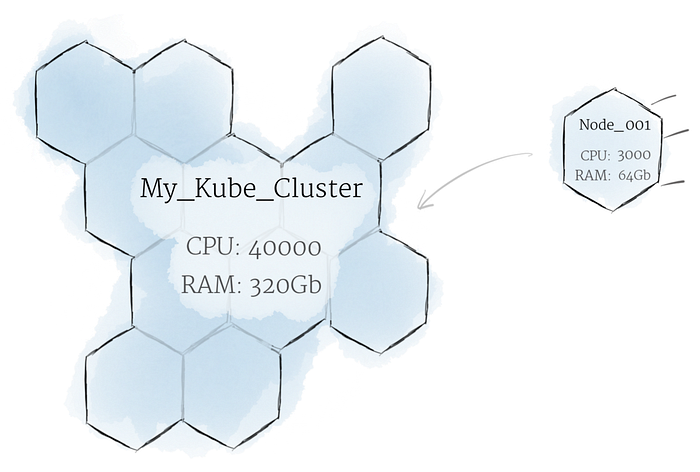
You should consider the cluster as a whole rather than the condition of individual nodes. In Kubernetes, nodes pool their resources to create a more potent machine. When applications are deployed to a cluster, the cluster automatically distributes work to the different nodes. If nodes are added or withdrawn, the cluster will reassign tasks as required to accommodate the desired state.
Given that programs cannot be guaranteed to operate on a given node, data cannot be stored in any file system location. If a program tries to store data in a file for later usage but is subsequently moved to a different node, the file will no longer exist where the application expects to find it.
Due to this, the conventional local storage linked with each node is viewed as a temporary cache for storing data, whilst any data that is finally retained is stored on Persistent Volumes. Local or cloud drives may be mounted to the cluster as Persistent Volumes — while the CPU and RAM resources of all nodes are effectively pooled and controlled by the cluster. Persistent Volumes provide a file system that may be mounted on the cluster without being connected to specific nodes.
Pods and Containers
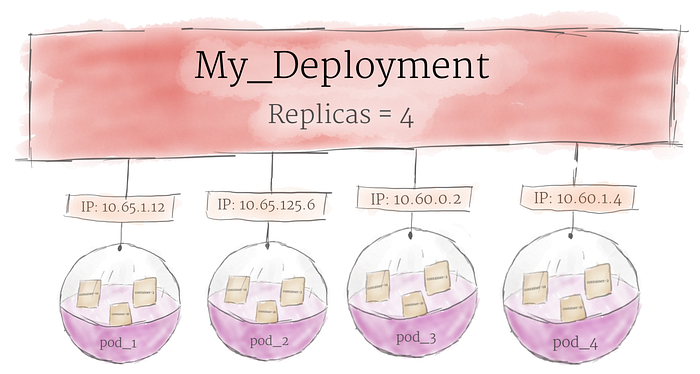
Kubernetes does not run containers directly, but it wraps containers into a higher structure called a pod. The same resources and local network are shared among the containers in the same pod. Pods are used as the minimum deployment unit and the unit of replication in Kubernetes. These containers can easily communicate with one another as if they were on the same machine, while still maintaining some level of isolation.
Pods can hold multiple containers but also be scaled up and down as needed, which multiple copies running at the same time in a production system to provide load balancing and failover. However, to avoid wasting resources and increasing costs, it is best to keep pods as small as possible, with only the main process and its closely related helper containers (side-cars).
Pods are not directly managed on a cluster, however, a deployment in Kubernetes is a higher-level abstraction that manages a set of identical pods. It typically ensures a specified number of replicas of the pods running at any given time, and can automatically handle scaling, rolling updates, and failover. A deployment also allows for more granular control over the desired state of the pods, making it easier to manage and update the application.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 8090The YAML file shown above is the object specification for a Pod. As mentioned earlier, a Pod can contain one or more containers. The specification includes plethora of properties including API version, the resource type (in this case, a Pod), metadata (like labels and resources name), and detailed specification of the sources. In the example provided above, the Pod is defined as having a container named nginx that uses nginx:1.7.9 Docker image, and opens container port 8090.
It is worth noting that the containers within a pod share the same IP and port, which means that if two or more containers are deployed through a single Pod, they can communicate with each other through localhost. If container A is deployed on port 8080 and container is deployed on port 7001, container B can call container A by using localhost:8080, and container A can call container by using localhost:7001.
Additionally, containers within a Pod can also share disk volumes. This is particularly useful when deploying applications which often come with helper utilities including reverse proxies and log collectors.
When deploying a web server using a Pod, it can be beneficial to have multiple containers to handle different aspects of the service. Example abounds in the following scenarios — one container could handle serving static web content, another could handle updating and managing the content, and a third can handle collecting log messages.
In this scenario, it is critical that containers can access and share the same files. By using volumes in Kubernetes, the shared directories like /htdocs or /logs shown above can be accessed by multiple containers within the Pod. This allows the different components of the services to work together seamlessly, improving the overall experiences and maintanences of the web server.
Services and Namespaces
Multiple pods are used to provide a Service and these are grouped together using a load balancer with a single IP and port. Pods are dynamically created and if an error occurs, they will automatically restart, causing their IP to be changed. Therefore, it is difficult to specify the list of pods in the load balancer using IP addresses. Additionally, due to auto-scaling, pods can be added or removed dynamically, whereby the load balancer must be able to flexibly select the list of added or removed pods.
When defining a service, the label selector is used to specify which pods to include in the service. Each pod can have labels defined in its metadata when it is created. The service selects only those pods with specific labels to include in the service.
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 9376The diagram shown above refers to the service only selects other services labeled myapp and provides service through load balancing among those pods.
Namespaces in Kubernetes, in contrast, can be deemed as logical divisions within a cluster. Pods, Services, and other resources can be created and managed within specific namespaces, and user permissions can also be assigned on a per-namespace basis. This allows for different environments including development, production, staging… to be operated within the same cluster by dividing into separate namespaces.
Using namespaces provides the benefits of managing access permissions for different users within the cluster. Namespaces also allow for the allocation of specific resource quotas, such as assigning 100 CPU cores to the development namespace and 400 CPU cores to the production namespace.
Control-Plane (formerly Master) and Worker Nodes
For appreciating Kubernetes, it is important to note the simple structure of clusters. There is a node called Control Plane, formerly Master, to control the cluster in general. The node is responsible for storing the configuration settings for the Kubernetes cluster and managing the overall cluster. It is composed of several components including the API server, scheduler, controller manager and etcd.
- API server is the central server that handles all of the commands and communication in Kubernetes — it provides all of the functionality of Kubernetes through REST APis and process the commands received.
- Etcd is a distributed key-value store that serves as the data store for the Kubernetes cluster, which stores the configuration settings and state of the cluster.
- Scheduler is responsible for assigning pods and other resources to appropriate nodes in the cluster.
- Controller manager creates and manages controllers such as the Replica controller, Service controller… and deploys them to individual nodes. It plays a role in maintaining the desired state of the cluster by continuously monitoring and making adjustments as necessary.
A worker node is where Docker containers are deployed and used as machines, which plays host to the workloads that run on top of Kubernetes such as pods and containers. It is a component that receives commands from the Control-plane and creates services that actual workloads.
- Kubelet is an agent that is deployed on the node. It communicates with the API server which receives commands to be executed on the node and reports the status of the node to the control plane.
- Kube-proxy is responsible for routing network traffic to the appropriate container and manage the network communication between the node and the control plane, and load balancing the incoming/outcoming network traffic.
- Container runtime is the component that runs the containers deployed through pods. The most common container runtime is Docker.
Additionally, kubectl us a command-line tool that acts as a bridge between you and the Kubernetes API, allowing you to perform any operations on a Kubernetes cluster. It helps you to create the necessary HTTP requests based on the command you give it, send the HTTP requests to the Kubernetes APIm and parse the response from the Kubernetes API and presents it to you in a human-readable format.
Introducing AWS kOps
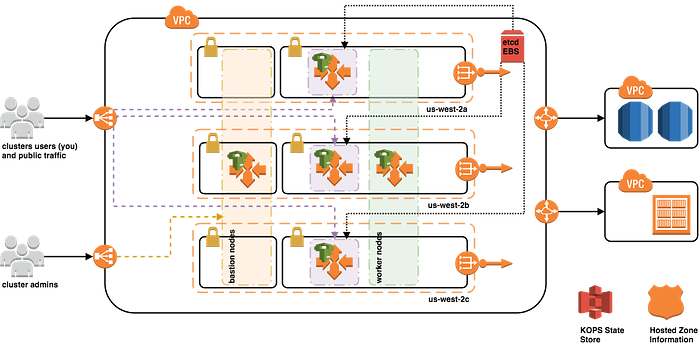
Managing a Kubernetes cluster across multiple regions and clouds can present a number of complex challenges — AWS kOps is a powerful tool that can help to simplify these tasks. Provisioning a Kubernetes cluster in cloud infrastructure can be challenging, as it requires dealing with instance groups, Route 53, ELBs… and more. kOps is a tool that streamlines the aforementioned process to set up a Kubernetes cluster in a production environment. It works by taking in certain parameters for the cluster and creating the necessary resources on the cloud to run the cluster. It has somewhat similarities to Terraform.
A KOPS-created Kubernetes cluster leverages the following AWS resource types:
- IAM Roles and Policies
- VPC, Subnets, and Routes, Route Tables, NAT and Internet Gateways
- Security Groups
- Route53 A Records (API, bastion)
- Elastic Load Balancers (ELBs), Auto Scaling Groups (ASG), Launch Configurations w/ defined user data
- Elastic Block Store (EBS) volumes for etcd primary data store and for etcd events
The advantage of utilizing kOps is that it creates the dedicated cluster as EC2 instances, which allows to access the node directly. One has the flexibility to choose the networking layer, the size of the nodes, and directly monitor the nodes. Additionally, one can easily scale up and down the AWS infrastructure by simply editing a file.
$ aws configure
AWS Access Key ID [None]: AKIA5...
AWS Secret Access Key [None]: CVNa2...
Default region name [None]: ap-northeast-2
Default output format [None]: json
export AWS_PAGER=""
echo 'export AWS_PAGER=""' >>~/.bashrc
export REGION=ap-northeast-2
echo 'export REGION=ap-northeast-2' >>~/.bashrc
export KOPS_CLUSTER_NAME=DOMAIN_NAME
echo 'export KOPS_CLUSTER_NAME=DOMAIN_NAME' >>~/.bashrc
aws s3 mb s3://BUCKET_NAME --region $REGION
export KOPS_STATE_STORE=s3://BUCKET_NAME
echo 'export KOPS_STATE_STORE=s3://BUCKET_NAME' >>~/.bashrc
kops create cluster \
--zones="$REGION"a,"$REGION"c \
--networking amazonvpc \
--cloud aws \
--master-size t3.medium \
--node-size t3.medium \
--node-count=2 \
--network-cidr 172.30.0.0/16 \
--ssh-public-key ~/.ssh/id_rsa.pub \
--name=$KOPS_CLUSTER_NAME \
--kubernetes-version "1.24.9" -yIntroducing Helm
Helm is a package manager for Kubernetes that allows developers and infrastructure operators to more easily package, configure and deploy applications services onto Kubernetes clusters. It is k8s equivalent of yum or apt — which deploys charts (a packaged application). When deploying an application on Kubernetes, it is required to define and manage several Kubernetes resources such as pods, services, deployments and replica-sets. Each of these require to write a group of manifest files in YAML format — it becomes a difficult task to maintain the plethora of YAML manifest files for each of these resources. This is where Helm plays a vital role in automating the process of installing, configuring complex k8s applications.
For example, You can search for the pre-packaged NGINX helm chart and install it after updating your helm repository.
$ helm search repo nginx
NAME CHART VERSION APP VERSION DESCRIPTION
bitnami/nginx 9.5.13 1.21.4 Chart for the nginx server
bitnami/nginx-ingress-controller 9.0.6 1.0.5 Chart for the nginx Ingress controller
bitnami/kong 4.1.9 2.6.0 Kong is a scalable, open source API layer (aka ...$ helm install nginx bitnami/nginx
NAME: nginx
LAST DEPLOYED: Wed Nov 17 01:12:56 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **You can also create a helm package and upload it in a public manner like the following. The folder named dodo-helm-tutorial is created, while numerous files are automatically generated but each with its own specific role.
- Chart.yaml — defining the information about the chart (name, version)
- charts — a directory where resource templates are stored
- NOTES.txt — defining the output displayed after the chart is installed
- .yaml — template files for resources to be deployed on the cluster
- values.yaml — a collection of variables used in the templates.
// https://spoqa.github.io/2020/03/30/k8s-with-helm-chart.html
$ helm create dodo-helm-tutorial
Creating dodo-helm-tutorial
$ tree ./dodo-helm-tutorial
./dodo-helm-tutorial
├── Chart.yaml
├── charts
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
3 directories, 9 filesUsing k8s structure in Microservices Architecture
When first learning about k8s and trying to deploy an application based on microservice architecture, the question was how many microservices should be placed in a single Kubernetes Pod. It is best practice to have one microservice per container (one container per pod), which allows for better isolation and management of resources. If a microservice container relies on something else, that should also be placed in the same pod.
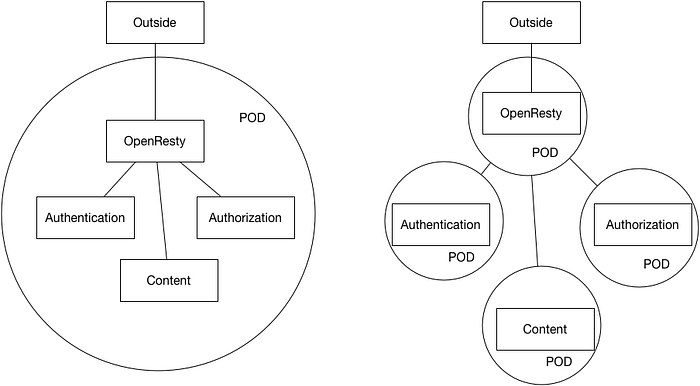
It is generally recommended to keep different services in different pods or better deployments that will scale independently. The reasons are what is generally discussed as benefits of a microservices architecture.
A more loose coupling allowing the different services to be developed independently in their own languages/technologies, be deployed and updated independently and also to scale independently.
The exception are what is considered a “helper application” to assist a “primary application”. Examples given in the k8s docs are data pullers, data pushers and proxies. In those cases a share file system or exchange via loopback network interface can help with critical performance use cases. A data puller can be a side-car container for an nginx container pulling a website to serve from a GIT repository for example. — Oswin Noetzelmann, Stackoverflow
It has been recommended to use Services for managing the communication between microservices. One can have only a single helm chart per microservices that helm chart will contain YAML files for everything related to the microservices but also for service. It is easy for the backend service to communicate with the rest of the services since the IP address of all the services will be injected into the environment variables of the backend container.
An abstract way to expose an application running on a set of Pods as a network service. With Kubernetes you don’t need to modify your application to use an unfamiliar service discovery mechanism. Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods, and can load-balance across them.
Personally, I love the architectural diagram shown here and here — each microservice has its own service while services manage the network traffic of pods, which shares the same docker container file.

Legend
- The dashed box: A logical Kubernetes cluster, running on multiple nodes
- Green boxes: Kubernetes services. They expose a set of one or more pods, typically through HTTP, for use by other pods
- Blue boxes: Kubernetes pods. Typically for us each pod runs one docker container, but if we need co-located applications they could run multiple containers
- Blue cylinders: Off-cluster database, in our case MongoDB. Each microservice has its own database provided by a single MongoDB cluster.
- Blue cloud: A cloud DNS provider, like Google Cloud DNS or Cloudflare
