Weekly Java: 트래픽이 많이 몰리는 이벤트가 예정되어 있을 때, Young Gen과 Old Gen의 비율 고민하기
튜닝의 끝은 순정이다
Question
- 트래픽이 무지 많이 몰리는 이벤트가 예정되어있을때, young gen과 old gen 비율은 어떻게 하는 것이 좋을까요?
My Answer
- 구태여 만지지 않겠다.
What is GC?
JVM은 메모리를 자동으로 관리해주기 때문에 GC가 성능의 입장에서 매우 중요하다. 사용되지 않는 객체들이 알맞은 시기에 메모리에서 정리되지 못하면, 프로그램이 정상적으로 동작하지 못할 것이다. 사용하지 않는 객체가 GC의 대상이 되지 않는다면, OOME (Out of Memory Error) 에 빠질 가능성도 있다. GC를 수행할 때 다른 Thread의 작업이 모두 멈추기 때문에 실시간으로 통신이 필요한 프로그램의 경우 Full GC가 일어나 수 초 동안 애플리케이션 정지가 이루어지면 여러 장애로 번질 가능성이 있다. GC가 완료된 이후 Thread가 복구되어도 수 많은 대기 요청에 따라 시스템이 크게 영향을 받을 수 있다.
일반적인 GC 과정은 Heap Area에서 더 이상 사용하지 않는 메모리를 제거하는 것이다. 우리가 일반적으로 알고 있는 Heap Area는 위의 이미지에서 볼 수 있듯이 Eden, Survivor의 두 영역, 그리고 Old Generation으로 구분된다. 여기서 Eden과 Survivor의 두 영역을 합쳐서 Young Generation이라고 일컫는다.
Java 8까지는 Parallel GC가 디폴트 GC 모델이었다. Parallel GC는 다른 CPU가 GC가 진행되는 시간 동안에 대기 상태로 남아있는 것을 최소화하려고 한다. Serial GC가 적용되어 하나의 CPU로 Young 영역과 Old 영역을 연속적으로 처리하면 STW가 발생하므로 프로그램의 정지가 이루어지기 때문이다. Parallel GC는 Serial GC의 Young 영역에서 진행하는 방식을 병렬로 처리하여 STW 부하를 줄였다.
일반적인 HotSpot VM에서의 GC의 동작 흐름을 정리해보면 다음과 같다.
- 맨 처음 객체가 생성이 되면 Eden 영역에 생성된다.
- Minor GC가 발생하면, 미사용 객체가 제거된다. 또한, 아직 사용되는 것으로 판단되는 객체를 Survivor 1 또는 Survivor 2 영역으로 이동시킨다. 만약, 객체의 크기가 Survivor 영역의 크기보다 크다면 Survivor 영역을 거치지 않고 바로 Old Generation으로 이동시킨다.
- Survivor 1과 Survivor 2 영역은 둘 중 한 곳에만 객체가 존재하며 다른 한 곳은 비어져 있어야 한다. 객체가 존재하는 Survivor 영역을 From 이라고 부르자. From 영역이 가득 차면 다른 Survivor 영역으로 객체를 보내게 되고, 기존의 Survivor 영역을 비우게 된다. 이 때 From 영역에서 객체를 받는 Survivor 영역을 To 영역이라고 부른다.
- 위의 1 ~ 3 과정을 반복하면서 Survivor 영역에서 계속 살아남는 객체들에 대해 일정한 score가 누적된다. 해당 score가 기준치 이상을 넘은 객체들에 대하여 Old Generation으로 이동시킨다.
- Old Generation 영역에서 살아남았던 객체들이 일정 수준으로 쌓이게 되면, 미사용된다고 식별된 객체를 제거하는 Full GC가 발생한다. 이 때 STW(Stop-The-World) 가 발생하게 된다.
이제 오늘의 주제에 대해 생각해보겠다. 트래픽이 많이 몰리는 이벤트라면 객체 생성이 많이 이루어진다는 의미다. 문제에서는 정량적인 형태와 비즈니스의 맥락의 관점에서 ‘많음’ 을 정의하지 않았기 때문에 구체적인 수치를 기반으로 답변하기는 어렵겠다. 하지만 비즈니스의 관점을 고민했을 때, 신규 고객 유치를 위한 마케팅 이벤트를 많이 핸들링하는 경우라고 생각해보자.
예를 들면, 암호화폐 거래소에서 최초 거래자를 대상으로, 당첨자를 무작위로 선정해 $100 USDC를 나누어주는 이벤트를 생각해보자. 이벤트에 참여하는 예비 고객은 거래소에 가입하는 행위만을 진행하고 서비스에서 이탈할 가능성이 높다. 따라서 트래픽이 많이 몰리는 이벤트에서 생성되는 객체들 중 대부분은 수명이 짧은 객체일 것이라고 생각할 수 있다.
수명이 짧은 객체가 많은 상황에서, 만약 Young Generation이 Heap 메모리에서 차지하는 비율이 작다면 Minor GC의 빈도가 증가할 것이라 예측할 수 있다. 이러한 경우, Minor GC에 의해 발생하는 STW의 빈도가 높아져 성능에 악영향을 줄 수 있다.
그렇다면 Young Generation이 차지하는 비율이 높이면 어떨까. Minor GC에 의한 STW 빈도수를 줄일 수 있을 것이다. 하지만 한 번 STW를 실행할 때마다 수거해야 하는 객체가 많기 때문에, 한 번 Minor GC를 실행할 때 필요한 STW의 시간이 길어질 것이다. 그리고, Minor GC의 빈도수가 적어지게 되면 Major GC의 빈도수가 높아질 것이라고 추측할 수 있다. Young Generation이 차지하는 비율과 Old Generation이 차지하는 비율이 서로 반비례할 것이기 때문이다.
결국 Young Generation에서 일어나는 Minor GC의 빈도수와, Old Generation을 대상으로 한 Major GC의 빈도 수 사이의 trade-off가 발생한다고 이해해볼 수 있다. 기본적으로 Major GC는 GC가 일어나는 빈도가 적은데, Old Generation의 메모리 할당률이 낮기 때문이다.
일반적으로 Old Generation은 Young Generation보다 메모리 용량을 크게 잡는다. 디폴트 값이 Young Gen:Old Gen이 1:3이다. 따라서 Old Generation에 객체의 갯수가 많기 때문에 GC 시간이 길다. GC의 시간이 길다는 것은 STW가 오래 걸린다는 소리이다. 또한, Old Generation은 별도의 Survivor Space가 존재하지 않기 때문에 메모리 단편화도 신경써야 한다. 또한 Major GC의 대상이 되는 객체들은 Minor GC의 객체보다 양이 많을 뿐더러 모두 살아있다. 따라서 Major GC에 들어가는 비용이 훨씬 클 것이라고 유추해볼 수 있다.
Major GC는 Heap 메모리가 모두 찼을 때 발동되기 때문에, Major GC는 최대한 발동되지 않고 Minor GC가 많이 발동되도록 하는 것이 순리상 맞다. 즉 생명 주기가 짧은 젊은 객체는 Old Generation으로 올라가기 전에 Young Generation에서 제거 되게끔 하고 오래된 객체의 경우 Old Generation에 상주시켜 상대적으로 아주 저렴한 Minor Garbage Collection 만으로 heap의 유지가 가능하게 유도하는 것이 좋다.
HotSpot VM에서는 Weak Generational 가설에 따라 Young Generation의 GC가 자주 일어날 것이라고 가정했다. 따라서 수행 시간도 매우 짧게 구현해야 할 것이다. 수행 시간이 짧으려면 한 번 GC 작업을 수행할 때 수거해가는 객체의 수를 줄이면 된다. 객체의 수를 줄이려면 영역의 사이즈도 줄이면 된다. Young Generation에서 GC를 자주 수행할 수록 메모리 단편화 문제가 발생할 수 있기 때문에, Survivor 영역을 만들어 Eden 영역에 생존한 객체를 모두 옮김으로서 GC 이후 Eden 영역의 제일 처음부터 할당할 수 있도록 구현했다. 어떤 이유에서 Survivor 영역이 생겼고, 또 Survivor 영역이 2개가 있을 지 고민해보면 좋다.
What is G1 GC?
Java 9부터는 G1 GC가 디폴트 GC 모델이다. G1 GC는 기존의 HotSpot VM의 개념은 유지한다. 즉, 객체의 크기가 너무 큰 경우를 제외하고는 최초의 객체가 생성되면 Eden 영역에 할당하고 이후에 Survivor 영역으로의 이동 및 소멸, 그리고 Old Region로 이동하는 생명주기를 유지한다. 따라서, STW를 완전히 없앨 수는 없고 일시 정지의 시간을 최소화하는 것이 목표다.
하지만 G1 GC는 Heap Area를 Young, Old 영역으로 물리적으로 구분하지 않는다. 개념적으로는 존재하나 Heap Area를 일정한 크기의 region으로 나누어 논리적으로 구분하던 이전 GC 방식을 따르지 않는다. G1 GC는 Heap을 동일한 크기의 영역 N개로 나눈다. 집합의 꼴로 분할되어 연속된 가상 메모리로 존재한다. JVM의 Heap 메모리를 1MB 정도 크기의 region을 약 2000개로 나눠서 region별로 generation을 지정하여 상당히 효율이 좋지만 튜닝하는 게 까다롭다고 한다.
G1 GC는 살아있는 객체를 모두 마킹한 후에, Region 별로 얼마만큼 살려둘 지 알 수 있다. Region 중에 모든 객체가 죽어 유효한 객체가 없는 Region, 즉 Garbage만 남은 Region부터 회수한다. 메모리 회수를 먼저 하면 빈 공간 확보를 더욱 빨리할 수 있다. 빈 공간을 더 빨리 확보한다는 것은 조기 승격이 줄어드므로 Old Generation이 한가해진다. G1 GC는 전체 Heap 메모리에 대하여 GC를 수행하지 않아도 된다. GC를 꼭 해야 하는 Region에 대해서만 GC를 수행한다. G1 GC는 Old Generation에 대해서도 Memory Compaction을 수행하는데, 특정 Region에 대해서만 Compaction을 수행하므로 오버헤드가 줄어든다.
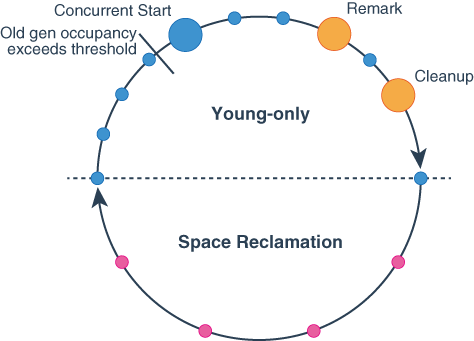
이제 G1GC가 어떻게 동작하는지 방식을 살펴보자. 이 글에서는 Oracle HotSpot VM에서 구현한 G1 GC 방식을 기준으로 설명하도록 하겠다. 공식 문서는 Oracle 문서를 참조했다. 일단 각 Region은 기존 JVM heap의 영역이었던 New Area(Eden Area), Survivor Area, Old Generation Area, Permant Generation Area를 각각 담당하나 동적으로 역할이 할당된다.
먼저 Young Only Phase다. 위의 사진에서 파란색 원은 Minor GC가 진행되면서 STW가 발생하는 상황을 의미한다. 주황색 원은 Major GC가 진행되면서 객체를 마킹할 때 발생하는 STW다. 빨간색 원은 Mixed Collection(Minor/Major GC) 을 진행하면서 발생하는 STW다. 평소에는 Minor GC만 수행하다가 -XX:InitiatingHeapOccupancyPercent 에서 설정한 값을 넘어가면 Major GC도 수행한다. Major GC는 Minor GC와 동시에 수행되며 모두 STW가 이루어진다. 이 때 Major GC는 Old Generation에 해당하는 객체를 마킹만 할 뿐이지 실제로 수거하지는 않는다.
다음으로는 Space Reclamation(공간 회수) Phase이다. Young Only Phase에서 마킹한 리전(Space)의 메모리를 수집(Reclamation)하는 단계다. Space Reclamation Phase에서는 Mixed Collection(Minor/Major GC)이 수행되는데 이는 빨간색 원이다. Space Reclamation 단계에서는 Mark 단계가 없기 때문에 STW 빈도가 줄어들었다. Space Reclamation Phase가 끝나면 다시 Young Only Phase로 돌아가서 Minor GC만 메모리를 수집하게 된다.
이렇게 G1 GC는 Young Only Phase와 Space Reclamation Phase를 번갈아 수행한다.
So What?
GC 튜닝은 애플리케이션의 성격과 구조에 따라서 좌우될 수밖에 없다. 그리고 tradeoff가 너무 명확하다. 트래픽이 너무 몰려서 서비스가 주기적으로 Hang이 걸리는 경우에는 핫타임 수용을 크게 하기 위해서 Heap Memory를 너무 크게 잡은 것이 아닌가 걱정하게 될 것이다. 이럴 때 Full GC로 사용자들이 불편하게 되니 Minor GC를 자주 수행하려고 하면, 오히려 Heap Size가 작아져 Hit Rate가 떨어지게 되어 전체적인 응답속도가 느려질 수 있다. 이는 사용자들이 또 불만을 가지게 될 요소가 된다.
따라서 정답은 없다. 결국 비즈니스 상황과 도메인에 좌우될 수밖에 없다. 에를 들어, 객체의 크기가 얼마나 되냐, 그래서 Old Generation이 얼마나 큰 용량이 필요한 가를 고민하는 것도 중요하다. 새로운 객체의 크기가 Survivor 영역에서 채울 수 없는 정도이면 Eden 영역에서 바로 Old Generation 영역으로 넘기기 때문이다.
파라미터 자체를 어떻게 설정하느냐 보다는, 비즈니스에 따라서 테스트와 로그를 통해 시스템의 성격을 파악하는 것이 중요하다는 원론적인 대답밖에는 떠오르지 않는다. 한 가지 확실한 것은, 어느 서비스에서 적용한 GC 옵션이 좋다고 우리 비즈니스에 덜컥 적용하는 것이 무의미하다는 것이다. 각각의 서비스에 할당된 WAS에서 생성되는 객체의 크기와 생명 주기가 각자 다르기 때문에 스레드 개수나 장비당 WAS 인스턴스 개수, 그리고 GC 옵션 등은 지속적인 모니터링을 통한 튜닝이 필요하다.
이는 비즈니스의 히스토리를 파악해야 한다는 이야기다. 레거시 시스템이란 진화를 멈춘 시스템을 의미하는데, 진화 중이더라도 시스템의 크기가 너무 커서 전체를 뒤집기 어려운 경우도 있다. 코드리뷰 문화가 훌륭하다면 미래의 가능성을 계속 고민하면서 시스템을 설계할 수 있겠다. 하지만 개발인력이 자주 교체되어 프로젝트의 히스토리를 파악하기 어렵기 십상이다. 변화가 많은 비즈니스 상황에서도 지속 가능한 소프트웨어 설계를 고민하려면, 결국 시스템이다. 개발팀의 코드리뷰 문화가 중요하다고 생각한다.
그래도 어느 정도 가이드를 내보자. Uber 기술 블로그에서도 공통적으로 객체 생성을 줄이는게 좋을 것 같다고 언급했다. 또한, Heap 메모리의 크기가 커질 수록 Young Generation 크기를 키우는 것이 좋겠다는 의견을 테스트를 통해 경험적으로 언급했다. 물론 대부분의 경우에는 각자 테스팅을 해보면서 알아갈 수밖에 없다고 적었다. 내 의견은 Full GC를 겪지 않는 것을 최대 목표로 잡고 튜닝을 시작하면 좋을 것 같다.
G1 GC는 Old Generation GC를 꼭 필요할 때만 실행하는데, 주로 New Area와 Old Area 비율이 InitiatingHeapOccupancyPercent 옵션에 해당하고, 기본값은 45다. 해당 Area 간의 비율이 일정 값 이하로 떨어지면 Young GC를 실행한다. Young GC를 수행하다가 Old Area가 증가하여 New Area가 감소하면 Old Generation GC를 통해 회복하고, 그래도 되지 않으면 Full GC를 활용해 회복하게 된다. G1 GC는 Region 개념 상 효과적으로 큰 메모리를 적은 pause time으로 관리할 수 있기에, Full GC를 최대한 피하는 방향을 택한다면 예상치 못한 장애 상황은 발생하지는 않으리라 생각한다.
만약 CPU 코어가 충분한 상태라면 ConcGCThread 나 ParallelGCThread 값을 높여서 GC를 수행하는 백그라운드 쓰레드의 갯수를 늘린다면 STW의 시간을 줄일 수 있을 것이다. 앞서 언급한 InitiatingHeapOccupancyPercent 옵션을 줄여서 Old Region에 대한 Concurrent GC를 자주 실행시켜 Full GC를 막을 수도 있다. 하지만 이러한 경우 old region 간에 쓰레드 경쟁을 발생시키므로 성능이 불안정해질 수도 있다. 하지만 Mark하는데 필요한 시간인 STW의 시간이 약 0.3초 가량인데 Concurrent GC는 이를 회피한답시고 매 번 수행할 때마다 수 분이 걸릴 수도 있다.
혹은 G1MixedGCCountTarget 나 MaxGCPauseMillis 를 활용하여 한 번 Mark하는 시간과 데이터 크기에 대한 상한선을 만들 수도 있다. 하지만 이렇게 구현하는 경우 Mark하는 빈도가 더 잦아질 수밖에 없다. 어려운 문제다.
G1 GC는 테스트해보면 별도의 파라미터를 지정하지 않아도 상당히 효율적으로 메모리를 관리하는 편이라고 한다. 이는 힘들게 파라미터 튜닝을 해도 효과가 잘 드러나지 않는다는 뜻이다. 내 의견은 순정이 최고라는 것이다. GC는 디폴트 옵션으로 사용했을 때 가장 효율적인 경우가 많으며, 구태여 GC를 튜닝하는 것보다는 객체의 재사용과 같이 코드 레벨에서 해결하는 것이 좋겠다.
